Python轻应用实现身份证识别¶
序言¶
HaaS 即 Hardware as a Service,它是加速AIoT开发者创新的一个积木平台。
Python轻应用是跑在HaaS积木平台上的一套应用框架。他是基于MicroPython进行开发,继承了 Python 优美简介的语法,同时提供了便捷的嵌入式硬件操作库。
HaaS100作为阿里云Iot推出的一款 Iot 开发板,它适配了MicroPython的运行引擎,提供了各种丰富的硬件操作接口,同时提供阿里云物联网平台和云端AI相关的能力。
通过这块芯片,我们可以轻松通过 Python 程序实现硬件控制,云端AI以及云端互通的能力。
今天我们就来讲解下,怎么基于 Python 轻应用框架,来实现文字识别(OCR)功能。
方案¶
总体思路¶
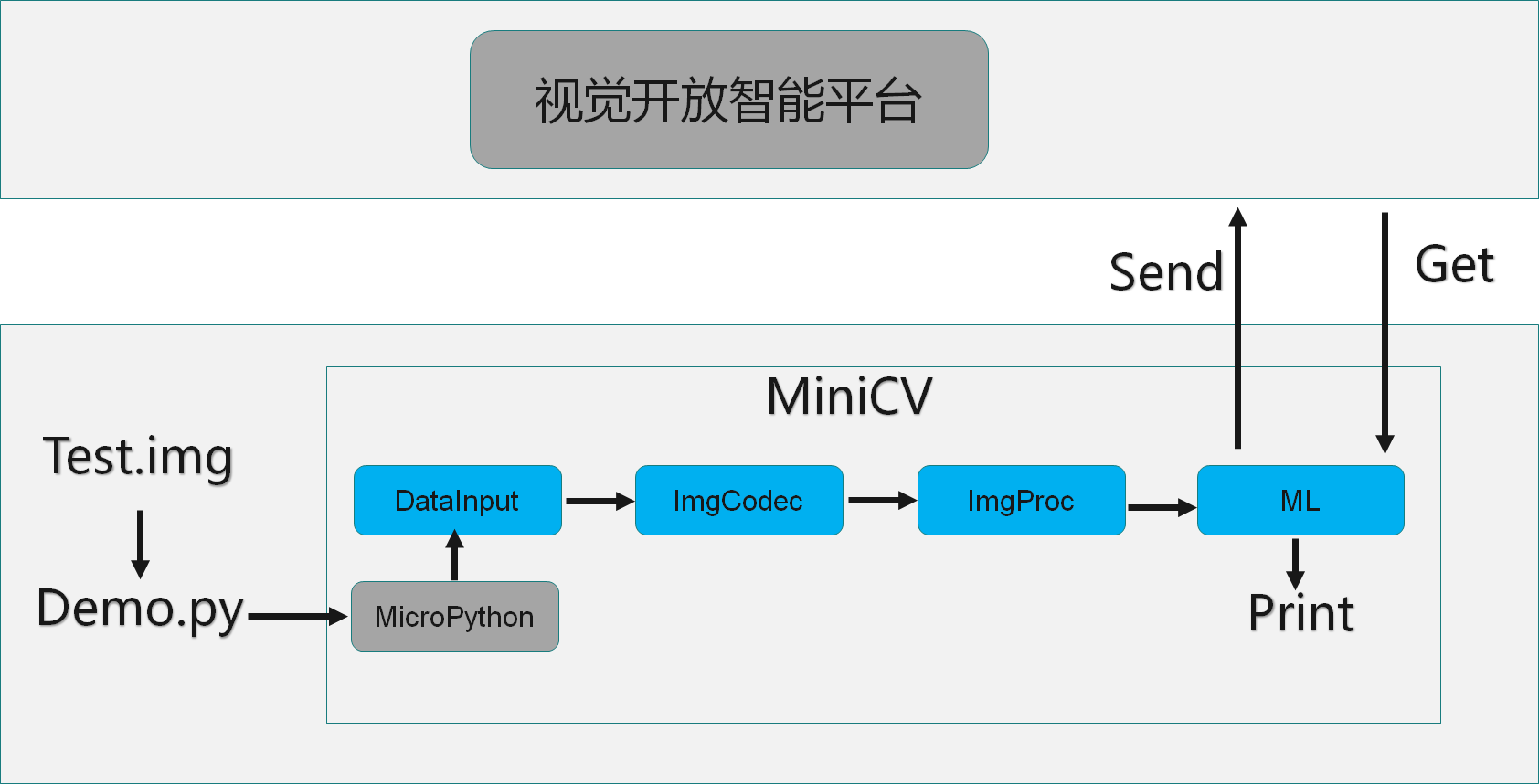
方案涉及主要涉及Minicv,Alibaba Cloud SDK 等功能模块。
MiniCV 是一套轻量级视觉框架,支持数据获取,图像处理,图像编解码,视频编解码,机器学习,UI呈现。
Alibaba Cloud SDK是阿里达摩院视觉智能开放平台的端上的引覆盖人脸、人体、视频、文字等150+场景。关于视觉视觉智能平台的详细信息可以参考官网:https://vision.aliyun.com/
数据处理流程为:通过MiniCV模块,完成数据源的封装处理,图片的解码,图片数据的格式转换和缩放等功能,最后将处理好的数据喂给ML 模块,ML 模块通过Alibaba Cloud SDK引擎和达摩院的视觉开放智能平台进行交互,得到预期结果。
由于HaaS100的板子默认没有配置LCD,所以为了方便开发者使用,通过打印LOG的方式将结果输出。
具备功能¶
文字识别技术基于阿里云深度学习技术,为您提供通用的印刷文字识别和文档结构化等能力。 文字识别技术可以灵活应用于证件文字识别、发票文字识别、文档识别与整理等行业场景,满足认证、鉴权、票据流转审核等业务需求
效果呈现¶
测试资源图片:”/data/python-apps/ml/recognize-character/res/test.jpg”

输出结果:
# -------------------Welcome HaasAI MicroPython-------------------- -----ml ucloud RecognizeCharacter demo start----- results size:1 index:0 probability:0.441612 text:飞猪旅行 left:199 angle:-5 top:166 height:373 width:781 bytearray(b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00') -----ml ucloud RecognizeCharacter demo end-----
OCR技术介绍¶
概念介绍¶
OCR是Optical Character Recognition的缩写,意思是光学字符识别,简称文本识别。
光学输入: 扫描仪,摄像机等
算法处理,文字提取和识别
文本输出
简单来说就是提取图像中文本信息。 一张图片上能涵盖的文本信息是非常多的,如果我们手工录入这些文本,势必会很慢。但是通过OCR,就能一次性获取图片中所有的文本信息,效率大幅提升。 正是由于OCR是一种非常快捷、省力的文字输入方式,所以在文字量比较大的今天,很受人们欢迎。比如说银行卡识别,身份证识别,电子名片等。
文本检测之DB技术分析¶
DB即Differentiable Binarization,从字面意思就可以知道,它的主要特点就是一个可变的二值化阈值。
它可以通过训练,动态设置不同场景,不同像素点的二值化阈值,从而更加精准的定位文本的位置。
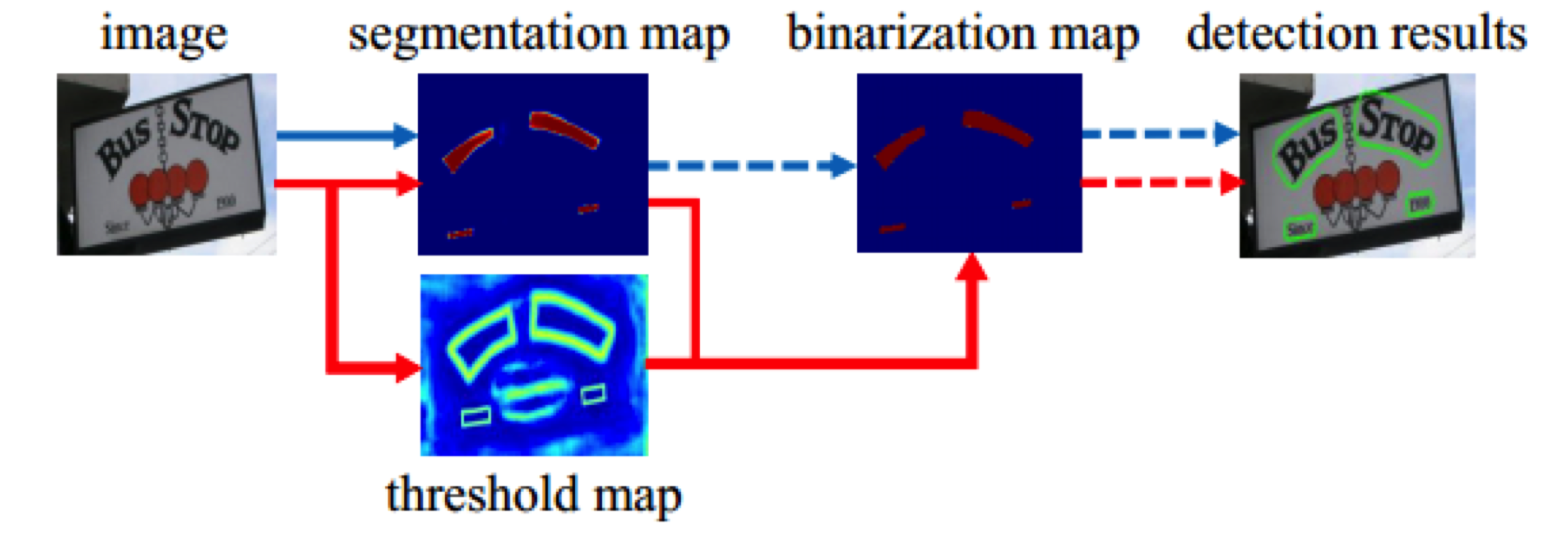
如上图所示:
蓝色箭头部分代表了传统的分割流程。
原始图–>分割图–>二值图–>目标图,在这个流程中,分割图到二值图的转换是通过一个固定的阈值来完成的,因此,当文字比较密集,并且不规则的时候,生成的二值图的文字边界就不太准确。
红色部分是DB的流程。它的主要功能就是在进行图片分割的同时,会基于文本边界生成一个动态的阈值图,也就是图中的threshold map. 通过segmentation map 和 threshold map 共同决定如何生成二值图。
segmentation map: 有文字的区域有值P
threshhold map: 文字边界才有值T
binary map: B = 1或者B=0
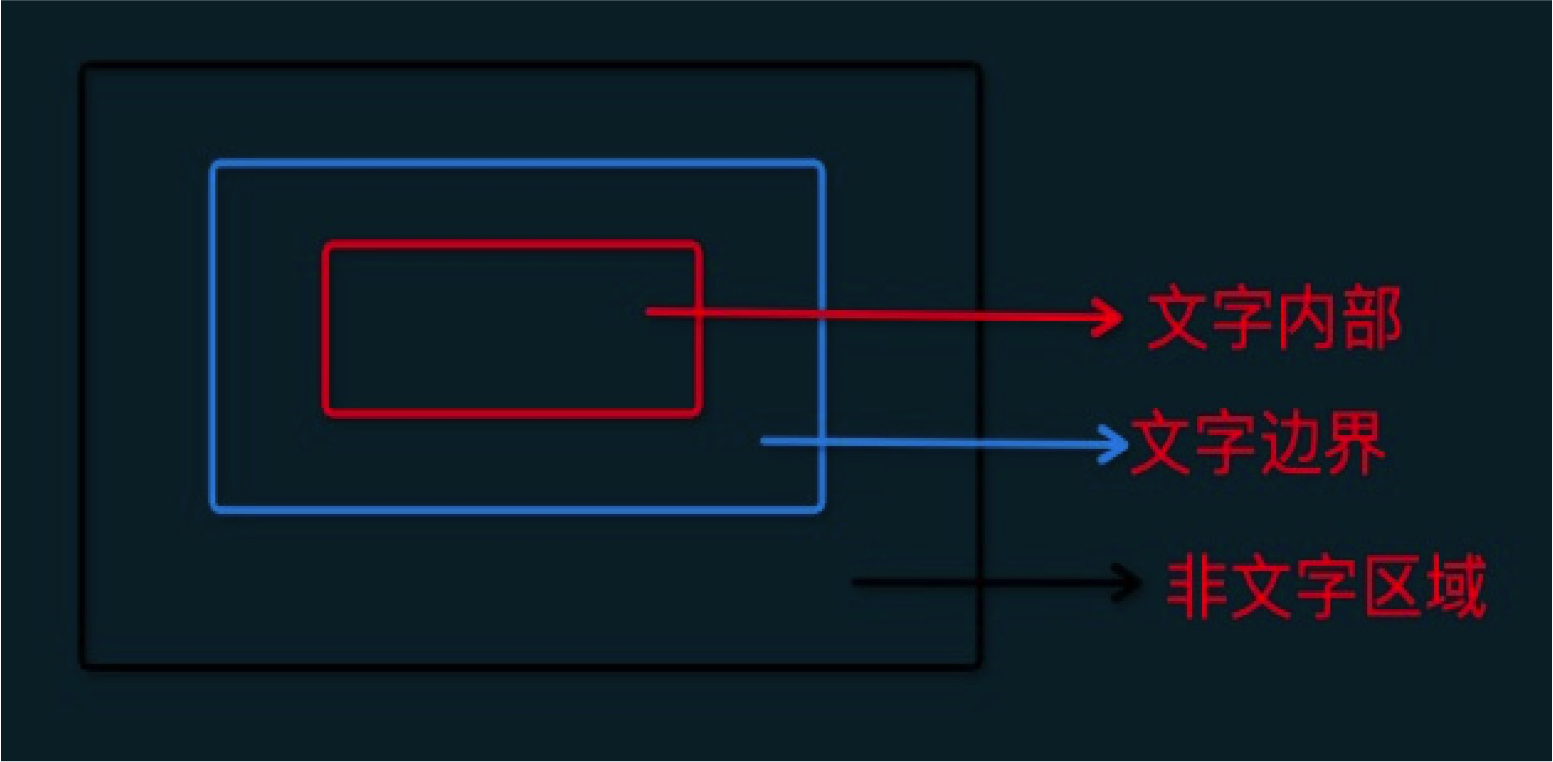
如果上图所示
文字区域内部:
P = 0.99 , T= 0.2 , P –T > 0, B = 1
文字区域边界:
P = 0 , T= 0.99 , P –T < 0, B = 0
非文字区域:
P = 0 , T= 0.2 , P –T < 0, B = 0
对于原始图中的每个像素点,都计算依据P 和T 值的不同,计算得到最终的二值图B,最后将二值图还原到原始图片中,生成精确的文本区域。
文本识别¶
文本识别指的是将 文本检测得到的文本框的的内容,转化为具体文字的过程。通常情况下,文本识别可以分为两大类:
定长文字的识别比较简单,使用场景也比较有限,常见的有验证码识别。这种文字识别的网络结果也会比较简单,可以参考LeNet ,构建一个CNN网络,通常情况下三个卷积和一个全连接层就可以实现,本文中不做详细介绍。
不定长文字识别
在日常生活,很多场景我们是不知道需要被识别的文字长度。因此我们需要一个更加复杂的网络,通过深度学习,自主判定文字的长度,并加以分割可转换。目前不定长文字的识别通常有两种实现方式:
CNN + Seq2Seq + Attention
CRNN这两种方法主要差别在输出层,他们都抛弃了softMax, 分辨采用拉Attention 和 CTC 来将序列特征信息转化为识别结果。Attention 由于机制原因,模型比较大,因此在Iot 端上我们采用的是CRNN 。
CRNN¶
CRNN(Convolutional Recurrent Neural Network,卷积循环神经网络)是目前比较流行的文字识别模型,不需要对样本数据进行字符分割,可识别任意长度的文本序列,模型速度快、性能好。 CRNN的主要特点是:
可训练
序列化识别任意长度字符,无需分割
速度快,性能好,模型小
CRNN模型主要由以下三部分组成:
卷积层:从输入图像中提取出特征序列
循环层:预测从卷积层获取的特征序列的标签分布;
转录层:把从循环层获取的标签分布通过去重、整合等操作转换成最终的识别结果。
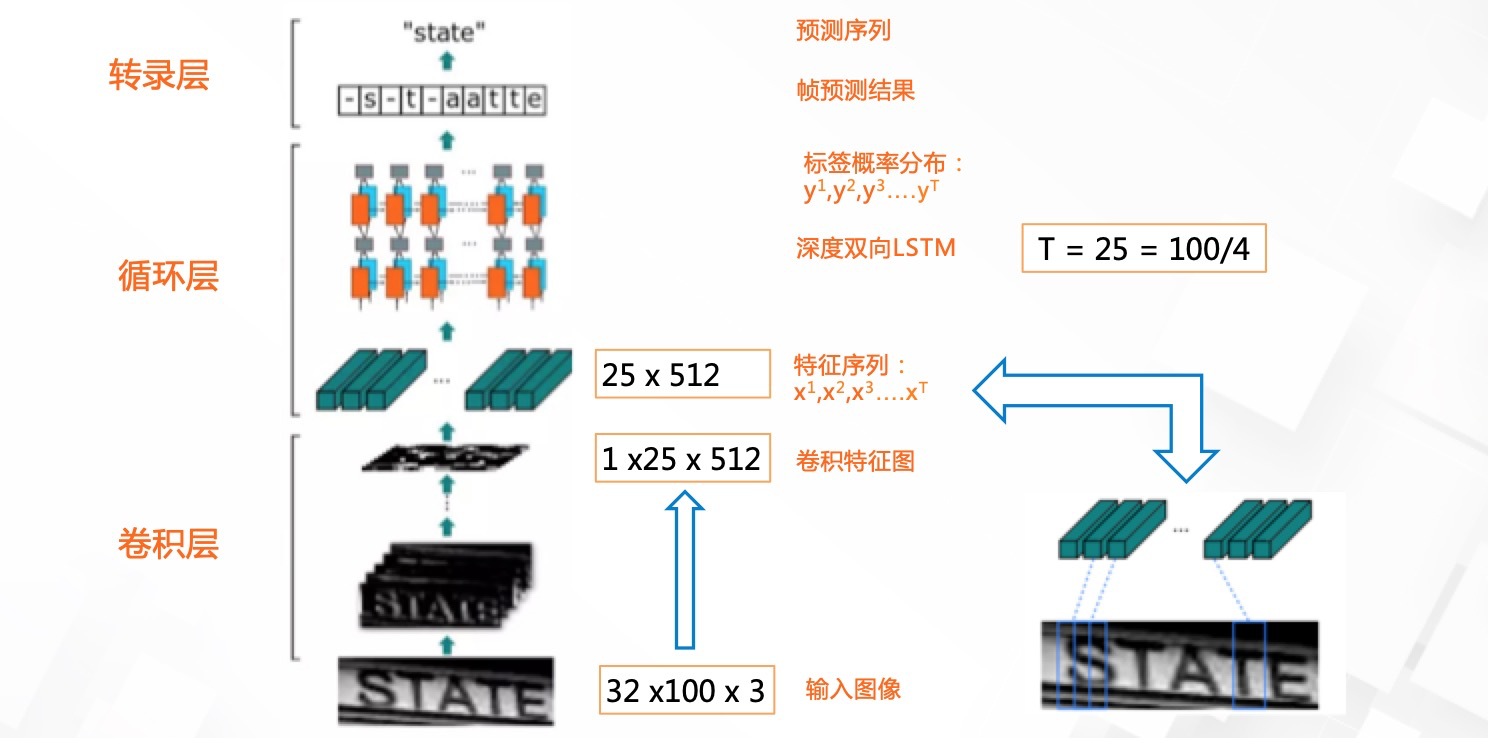
卷积层¶
1、预处理对输入图像先做了缩放处理,把所有输入图像缩放到相同高度
2、卷积运算7个卷积 加上 4 pooling , 引入 2 个bn(BatchNormalization) 加速模型收敛,缩短训练过程
3、 特征提取从左到右,按列生成特征向量,作为循环层的输入
循环层¶
循环层由一个双向的 LSTM 组成。
LSTM(Long Short Term Memory,长短期记忆网络)是一种特殊结构的RNN(循环神经网络),用于解决RNN的长期依赖问题, 也即随着输入RNN网络的信息的时间间隔不断增大,普通RNN就会出现“梯度消失”或“梯度爆炸”的现象
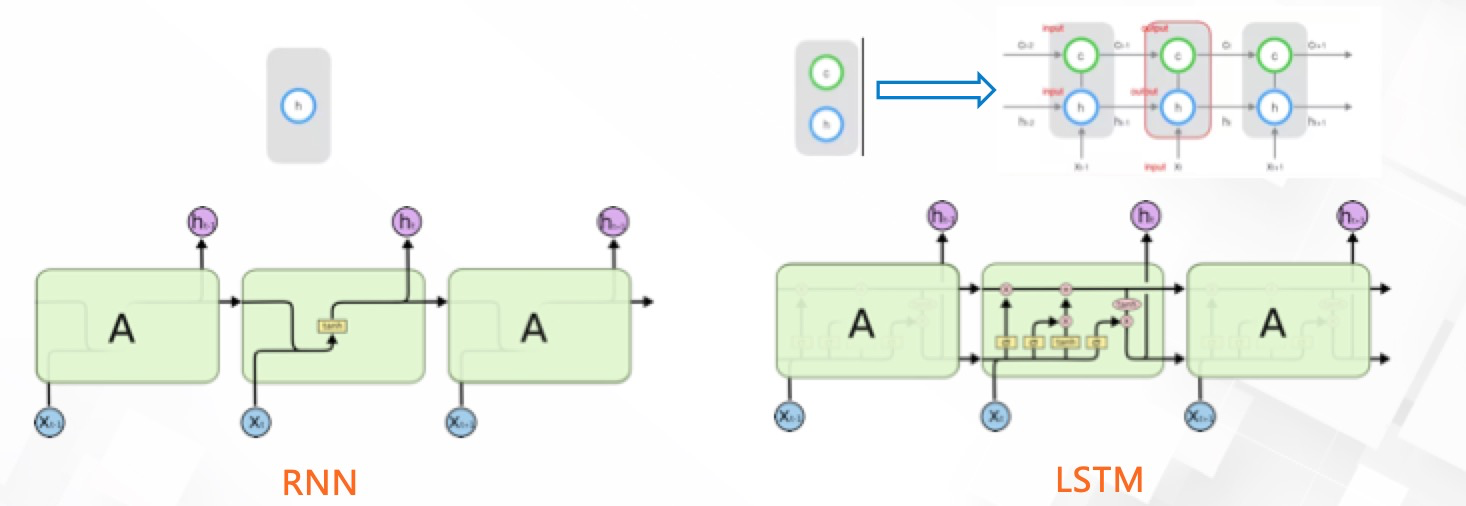
从上图可以看出,LSTM跟RNN最大的区别就是增加一个保存长期状态的单元,并且通过三个门开关,控制这个单元的状态
输入门:决定当前时刻的网络状态,保存多少到这个长期状态
遗忘门:决定上一个时刻的长期状态,保留多少到当前时刻的长期状态
输出门:当前的长期状态,有多少作为当前网络的结果输出
转录层¶
转录层是将LSTM网络预测的特征序列的结果通过CTC进行整合,转换为最终输出的结果。
CTC模型(Connectionist Temporal Classification,联接时间分类),主要用于解决训练时字符无法对齐问题。

如上图所示:
输入字符CTC ,由于字符间隔,图像变形等原因,导致经过CNN+RNN 处理后的结果变成–CC—-TT–CC
其中-代表空白区域,它是在CTC在训练阶段加上去的,目的就是为了避免解码的去重方便。
在解码阶段,先去掉连贯的重复字符,然后去掉插入的空白字符,最后得到识别结果CTC
Demo体验¶
参考 《HaaS100快速开始》 下载AliOS Things代码。
git clone https://github.com/alibaba/AliOS-Things.git -b dev_3.1.0_haas
编译代码:
make distclean make py_engine_demo@haas100 -c config make
编译完成以后,烧录完整的固件。通过串口输入:
python /data/python-apps/network/wifi/main.py wifi_ssid wifi_password python /data/python-apps/ml/recognize-character/main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | from minicv import ML
print("-------------------Welcome HaasAI MicroPython--------------------")
print("-----ml ucloud RecognizeCharacter demo start-----")
OSS_ACCESS_KEY = "xxxx"
OSS_ACCESS_SECRET = "xxxx"
OSS_ENDPOINT = "xxxx"
OSS_BUCKET = "xxxx"
ml = ML()
ml.open(ml.ML_ENGINE_CLOUD)
ml.config(OSS_ACCESS_KEY, OSS_ACCESS_SECRET, OSS_ENDPOINT, OSS_BUCKET, "NULL")
ml.setInputData("/data/python-apps/ml/recognize-character/res/test.jpg")
ml.loadNet("RecognizeCharacter")
ml.predict()
responses_value = bytearray(10)
ml.getPredictResponses(responses_value)
print(responses_value)
ml.unLoadNet()
ml.close()
print("-----ml ucloud RecognizeCharacter demo end-----")
|
设备端配置¶
注册链接:https://www.aliyun.com/ 点击红色框圈中的“立即注册”按钮进行注册.
使用OSS功能的时候涉及到四个配置参数:AccessKeyId,AccessKeySecret,Endpoint,BucketName.
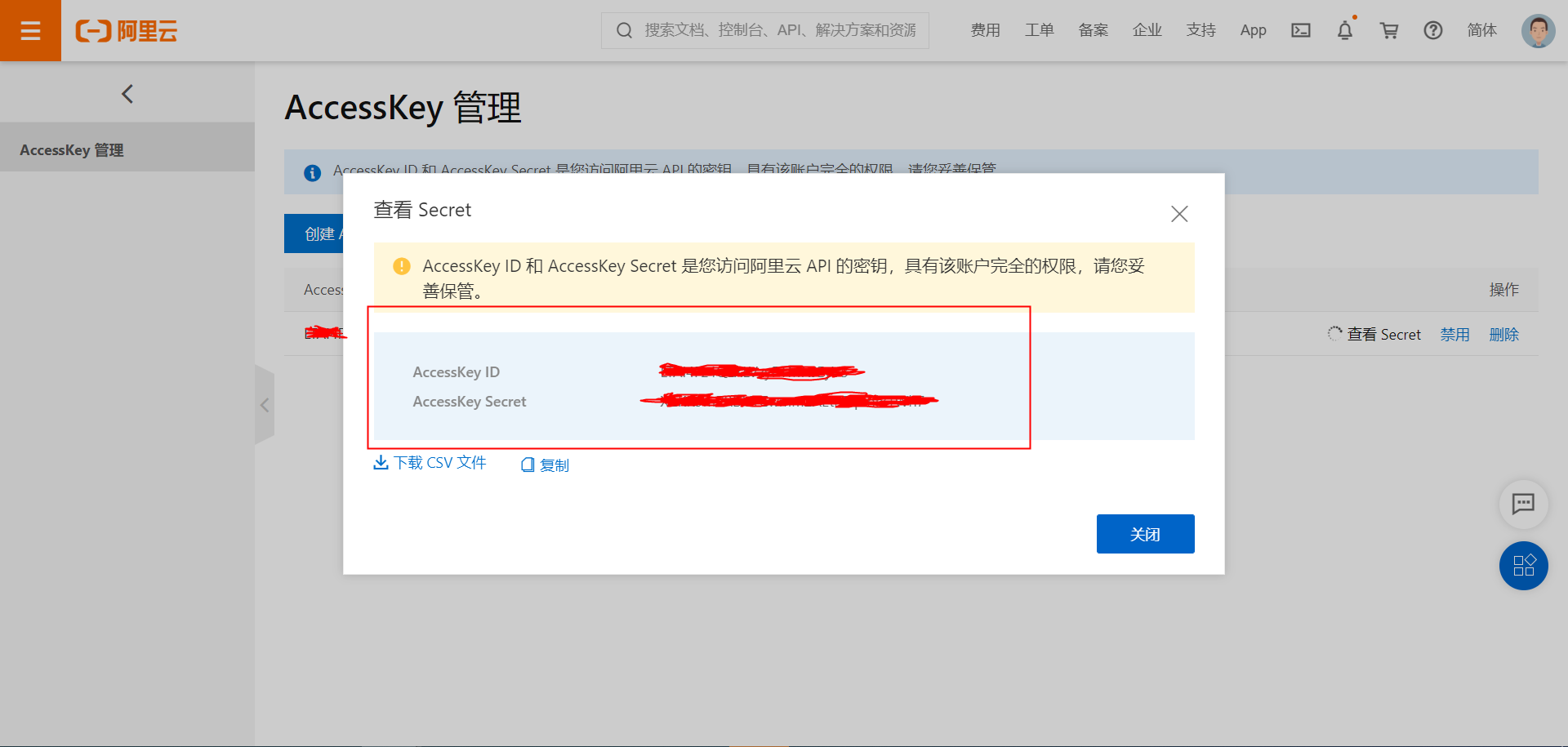
AccessKey 获取:登录https://ram.console.aliyun.com/ 账号管理平台查看AccessKeyId,AccessKeySecret(账号为上一节中注册的账号),点击账号头像框中的”AccessKey管理”按钮.
点击按钮”查看Select”,获取AccessKeyId,AccessKeySecret
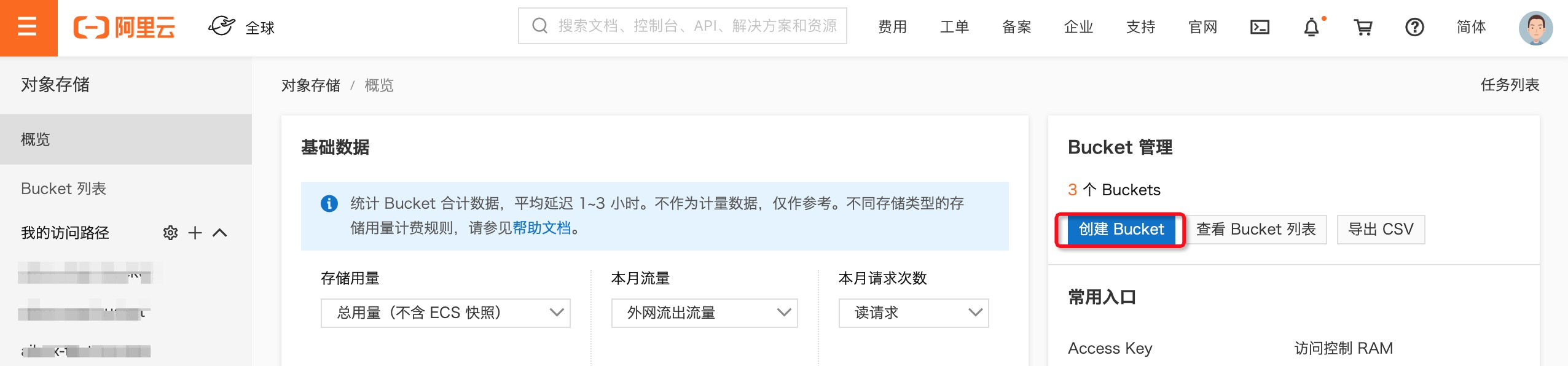
Bucket账号获取: 登陆OSS控制台https://oss.console.aliyun.com/创建Bucket,创建时地域 一定要选择上海
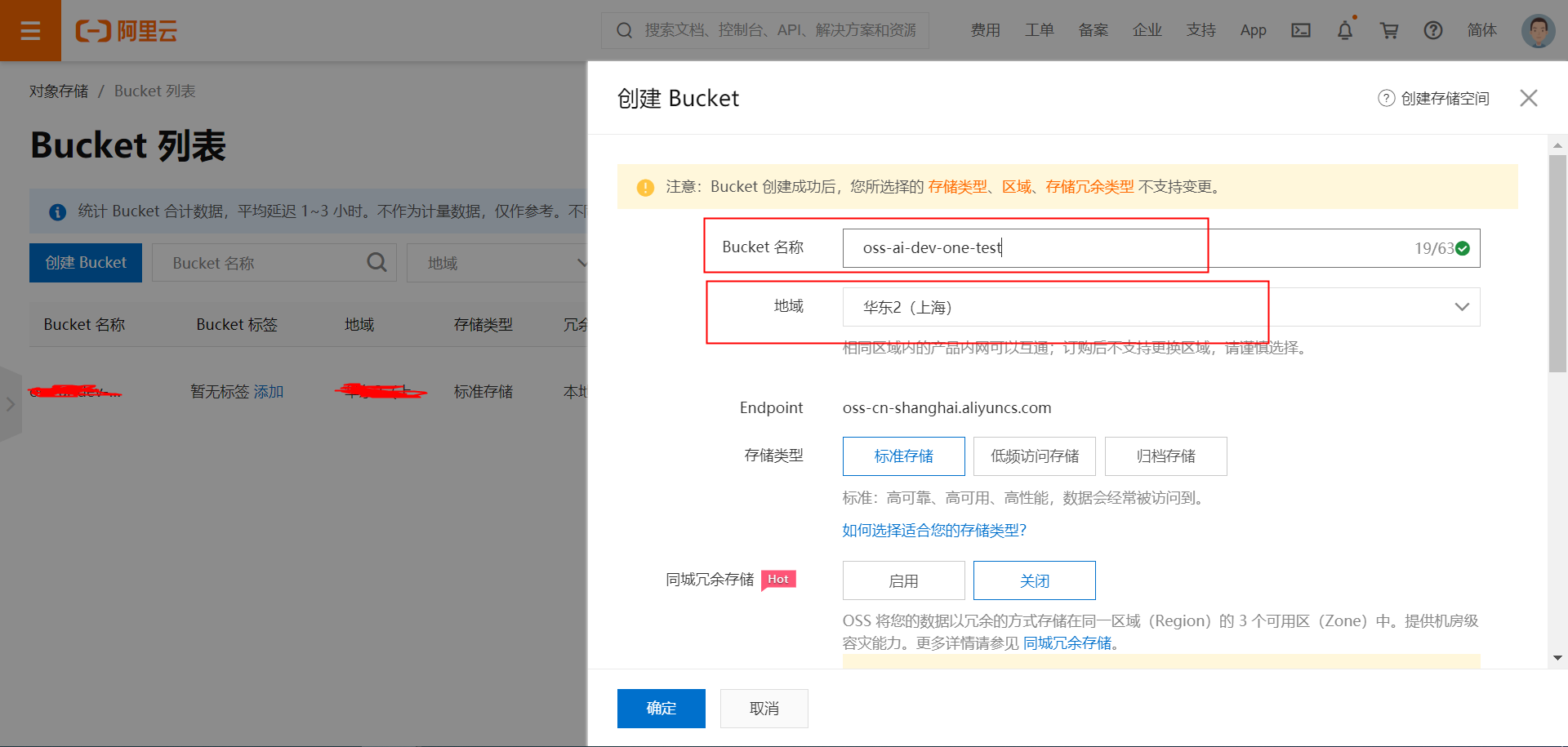
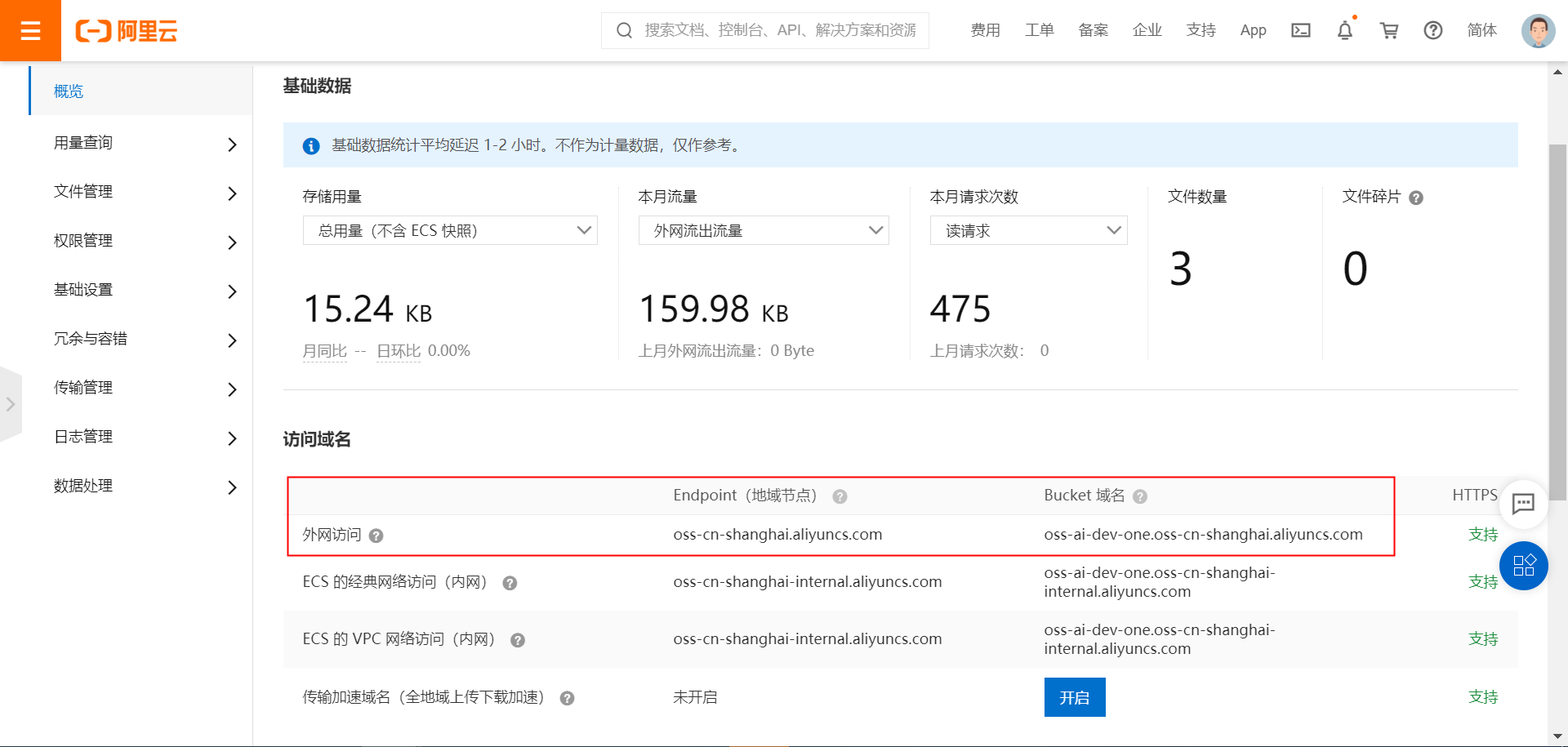
在Bucket创建好后,从上图我们可以看到:
Endpoint:oss-cn-shanghai.aliyuncs.com
BucketName就是我们创建Bucket取的名字oss-ai-dev
创建好文件夹后,记住一定要修改文件夹权限,否则访问失败.