KV结构模板-用户白皮书
产品介绍
KV结构模板是阿里读光OCR提供的一款用于对关键要素进行定向提取的自定义模板产品,主要针对文档、表单、票据、卡证等类型的图片。 用户可以使用KV结构模板对图片进行模板配置和数据标注,经过训练、评测和发布后,可获得对应的模板ID,并使用API接口批量调用同类图片来进行关键要素的key-value键值的结构化输出。
产品范围
适用于相同类型的图片,即图片版式基本保持一致。 图片版式差别较大的(如各个医院的医疗发票)不在KV结构模板的产品范畴内。
产品亮点
KV结构模板的产品亮点:
- 基于专家规则和深度学习的可视化模板产品
- 小样本模型训练,保障识别率的同时降低用户成本
- 用户参与式全模板配置过程,实时数据反馈与效果评估
- 模板可用性高于80% (可用性指标为KV字段识别率/OCR识别率,是衡量模板有效性的指标)
产品步骤
KV结构模板的使用步骤主要分为如下几步:
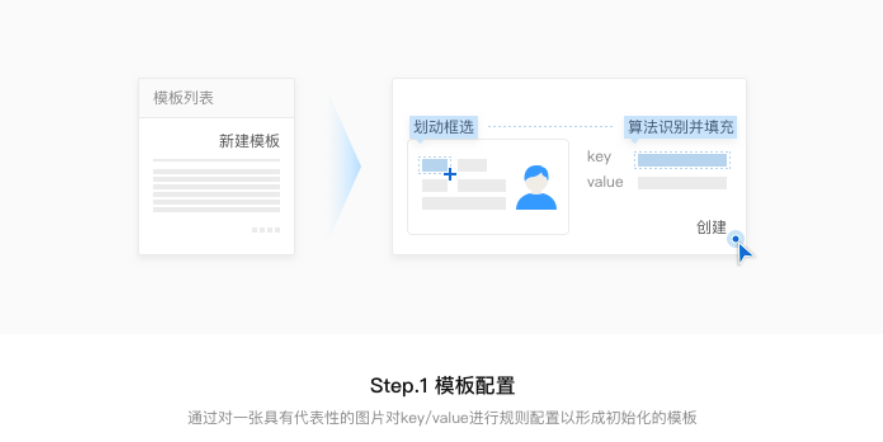
- 模板配置。通过对一张具有代表性的图片进行key/value的规则属性配置,形成初始化的模板;作为配置的图片最好选择清晰、无遮挡、无反光的图片更有利于模板的配置。
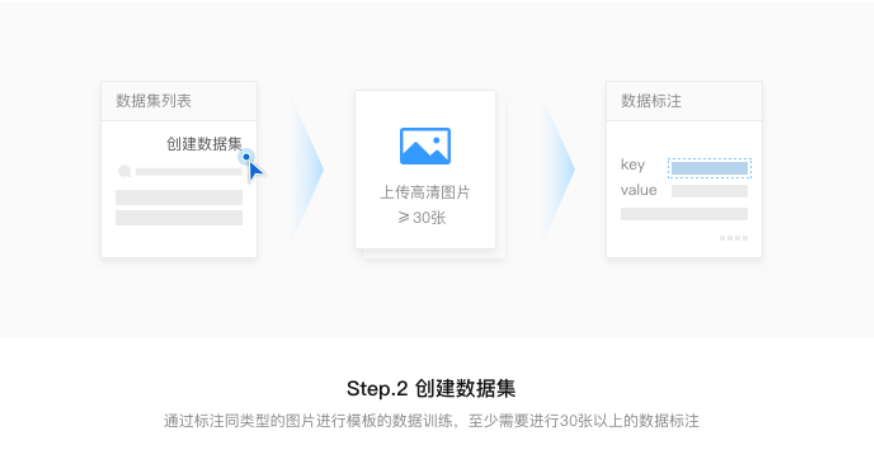
- 创建数据集。通过标注相同类型的图片进行模板的数据训练,因此第二步需要创建数据集(训练数据至少30张),通过标注训练图集上的value值,形成一批可用的训练数据。这些已标注好的数据会按比例分成训练数据和评测数据。
- 模板训练。模板训练是基于深度学习算法进行的机器自学习过程,系统会根据标注数据自动强化模板的识别率,提高模板的容错性。训练集的数据越多对模板训练的效果就越佳,为了达到理想效果,建议至少100~200张训练数据。训练是个反复的过程,可以分多个批次进行训练,每个批次建议上传更多的图片进行标注以达到自学习的目的。

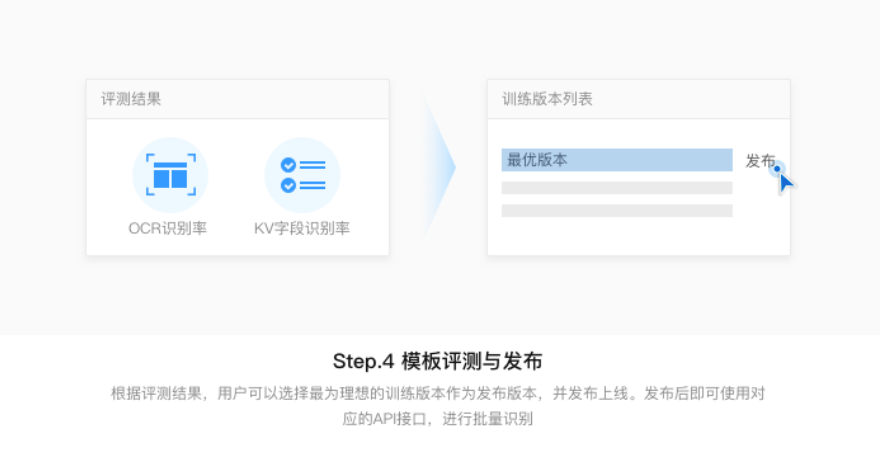
- 模板评测与发布。模板评测是用于对经过训练的模板进行效果评测打分的步骤。在每个训练批次中可实时查看效果评估对比。评测指标分为OCR识别率和KV字段识别率,OCR识别率是文字本身的识别效果,KV字段识别率是指模板在评测过程中所有字段的平均识别结构。通常情况下,KV字段识别率/OCR字段识别率>80%,是较为可用的状态,当然用户可根据自己的标准进行效果评估。根据评测结果,用户可以选择最为理想的训练版本作为发布版本,并发布上线。发布成功后即可获得模板ID,使用对应的API接口,即可调用该模板进行批量识别。
名词解释
| 名词 | 解释说明 |
|---|---|
| 固定格式模板 | 指图片中的Key的名称、key之间的空间位置相对固定的。如新版营业执照、增值税发票、身份证这类。 |
| 多样式模板 | 指图片中key的名称、key之间的空间位置关系差异较大的,即属于多样式模板。如各个医院的医疗发票、全国各地的房产证等。此类图片不适用于KV结构模板。 |
| 模板图片 | 模板图片是首张用于配置的示例图片,模板图片需要确保字迹清晰,图像端正、无遮挡。 |
| key | key是图片上所需的关键键值的名称。如身份证中,“姓名”为key。 |
| value | value是所选的key对应的字段值。如身份证中,“支小宝”就是value。 |
| value属性 | value属性是系统根据文字的实体信息给出的属性值,会有一些纠错的逻辑。目前value属性值包含常见的8大属性集合。 |
| 标注数据 | 标注数据是指将图片上的文字通过标注的方式人工记录下正确值。 用户可使用框选更为便利地帮助标注工作。 |
| 识别质量分 | 识别质量分是指根据文字识别的结果倒推判断图像质量的行为。低质量分的图片可认为识别质量较差,不利于进行模板训练。因此尽量选择高质量图片进行数据标注(质量分>=70分)。 |
| 训练评测比 | 即已经标注好的可用数据用于训练和用于测试的数据比例。比如30张数据,训练评测比为80%,则24张用于训练,6张图用于测试。 |
| OCR识别率 | 具体某个字段纯OCR识别的结果在该字段检索中的文字匹配率(用于验证底层ocr效果好不好) |
| KV字段识别率 | 指由模板识别的结果与用户录入的结果进行比对,正确图片的数量/所有图片(用于验证模板配置的效果) |
| 模板可用性指标 | 通常若KV字段识别率/OCR识别率>80%,则认为模板配置可行 |
具体操作
1. 模板配置
在进行KV结构模板的模板配置前,需要先明确本次所需配置的模板是属于固定格式模板还是多样式模板。若为固定格式模板,则选取一张字迹清晰、图片端正的主图作为模板图片。主图图片格式可以为png,jpg,jpeg等图片格式,大小不超过4M,最长边不超过4096像素。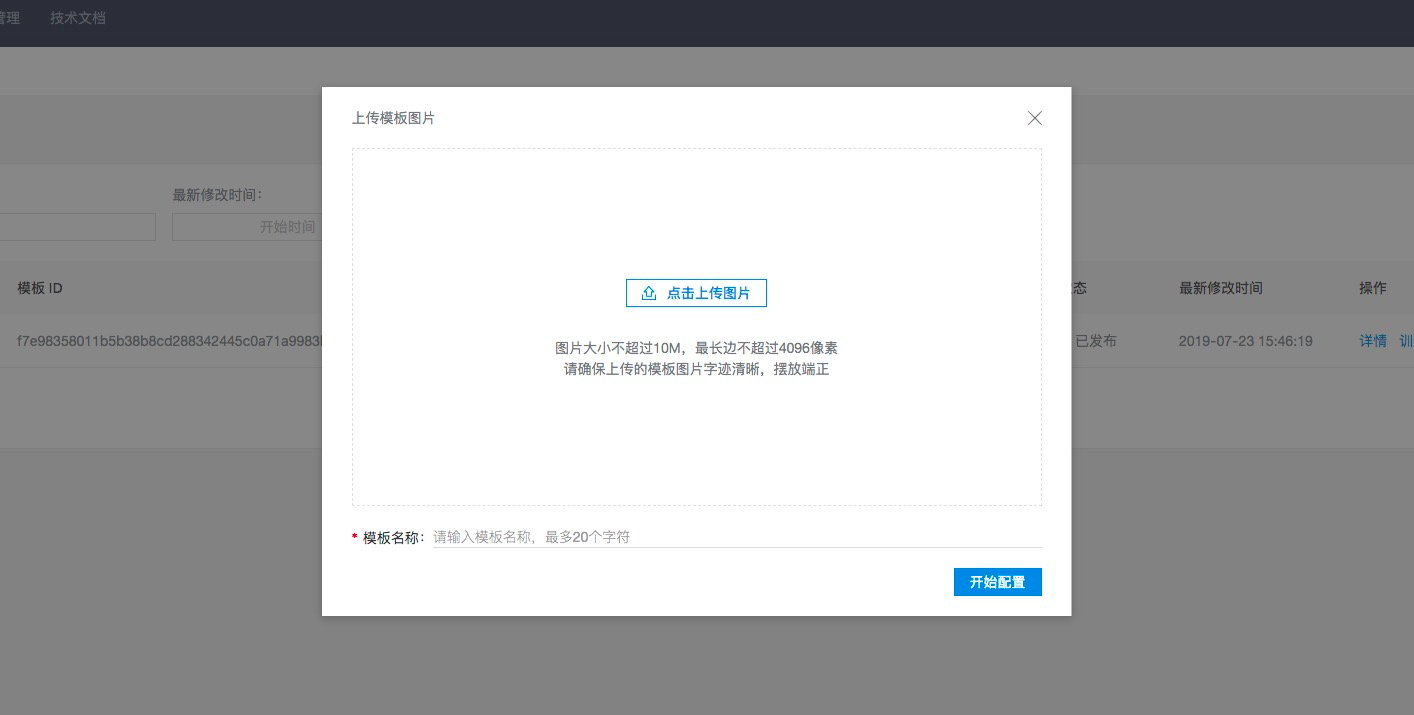
上传好后即进入模板编辑页面,此时需要配置在该图中所需的字段组合在图片中的key和value分别对应的位置,并框选出来。以营业执照为例:
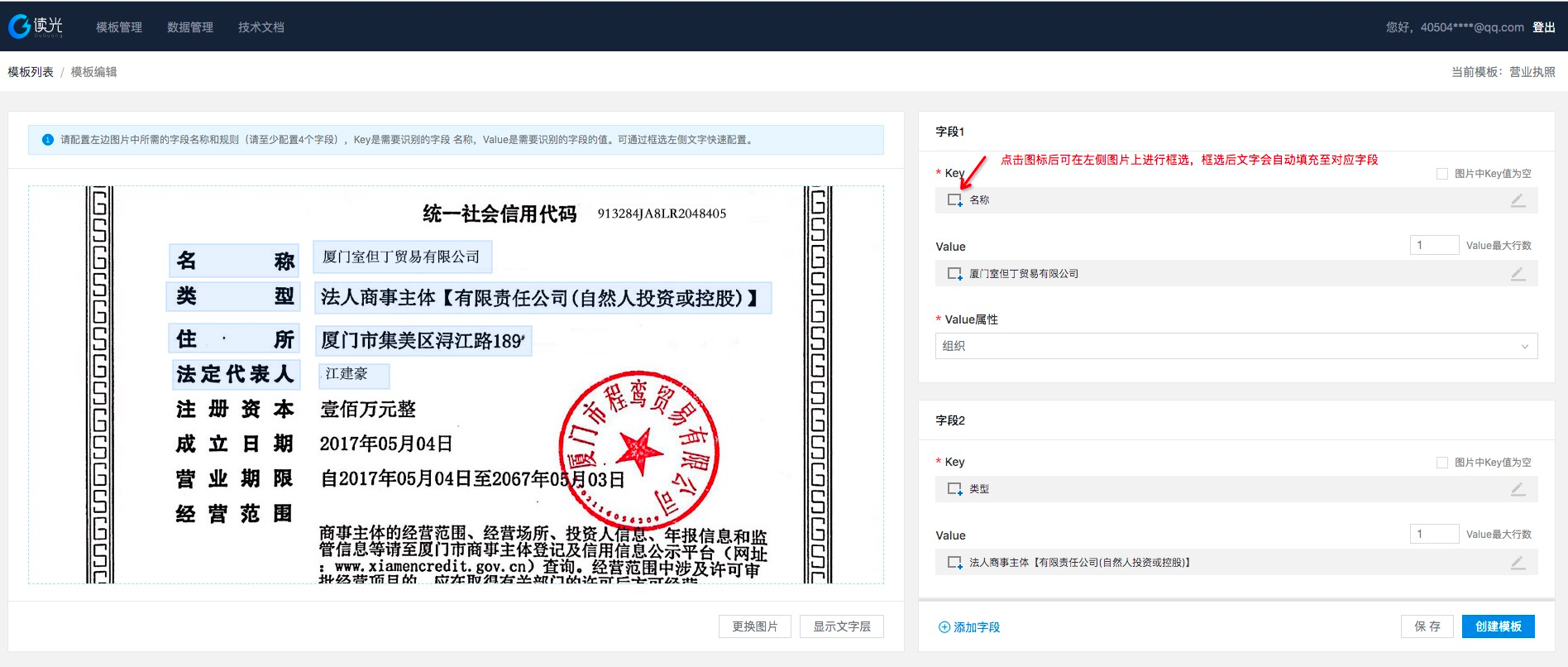
说明:
- 使用框选的时候,点击右边部分的框选按钮即会触发左侧的框选锚点。通过框选后,系统将自动填入到所选的字段中。若自动识别错误,用户可点击编辑按钮进行文字更正。
- 存在图片中没有key,但有value的情况(如标题字段),则需要在key中填写“标题”,并勾选右上方
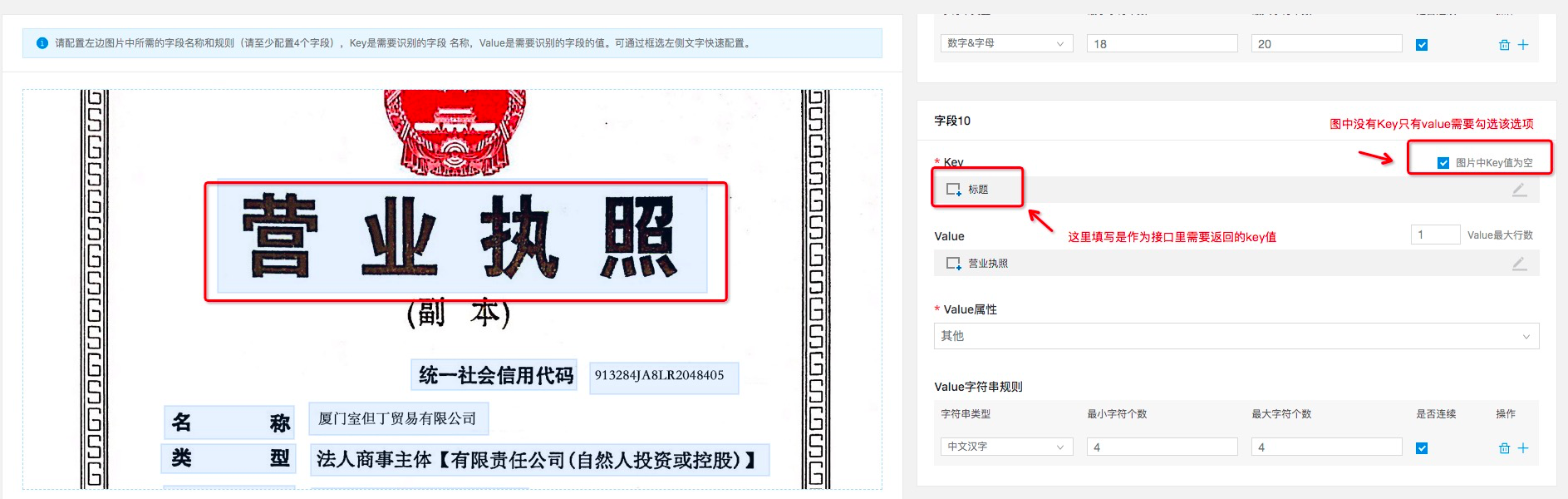
- value属性系统将给出常见的默认属性值,包含如下八类:
- 姓名(指代个人类的姓名)
- 组织(指代企业类的组织名称)
- 地址
- 民族
- 性别
- 日期
- 身份证号码
- 金额
若所选的value属性不包含在上述8类,可选择其他,并设置该value字段值的字符规则类型和字符长度。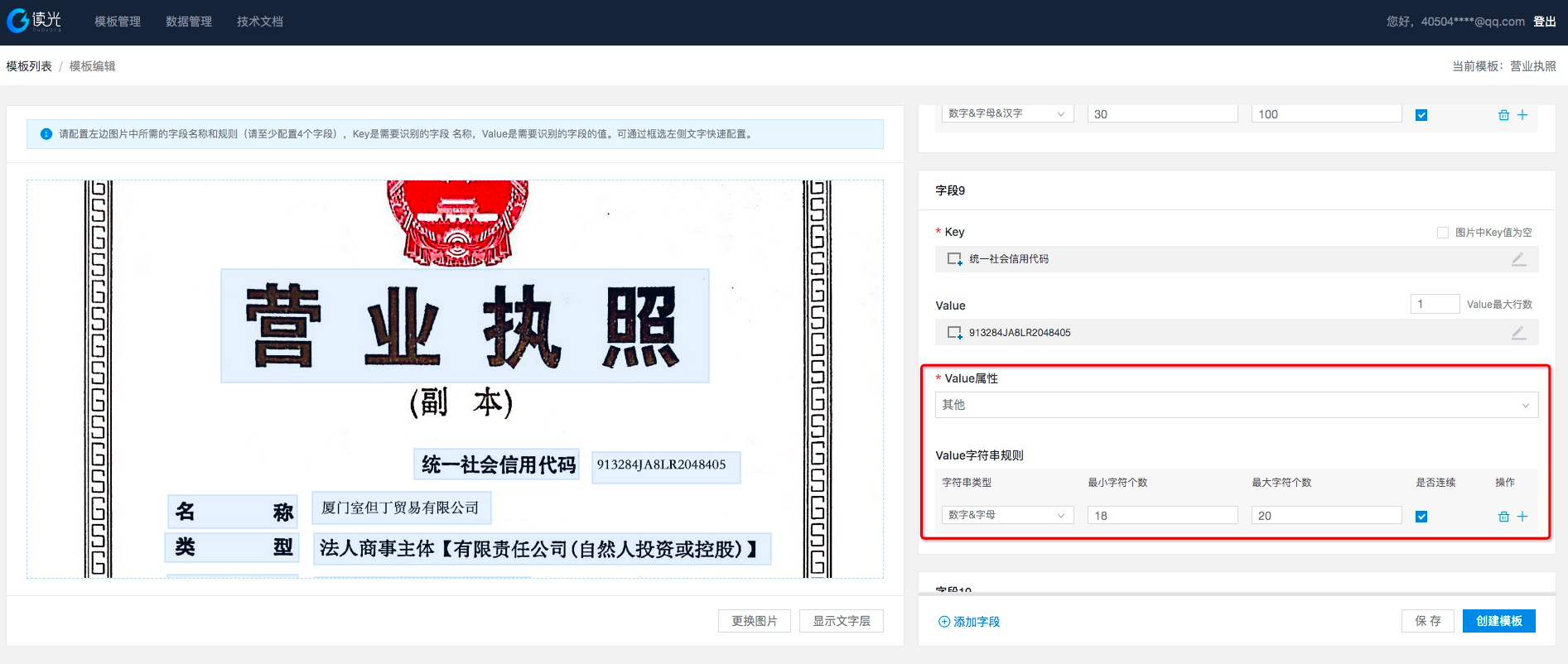
是否连续是指字符之间是否会出现空格、标点符号等字符,若会出现则选择不连续
- value有时候会有多行的情况,因此在配置的时候需要充分考虑可能的情况,常见的地址、经营范围类可能都会在不同图中出现多行。针对这类的字段,需要用户给出最多可能多少行的设置值。
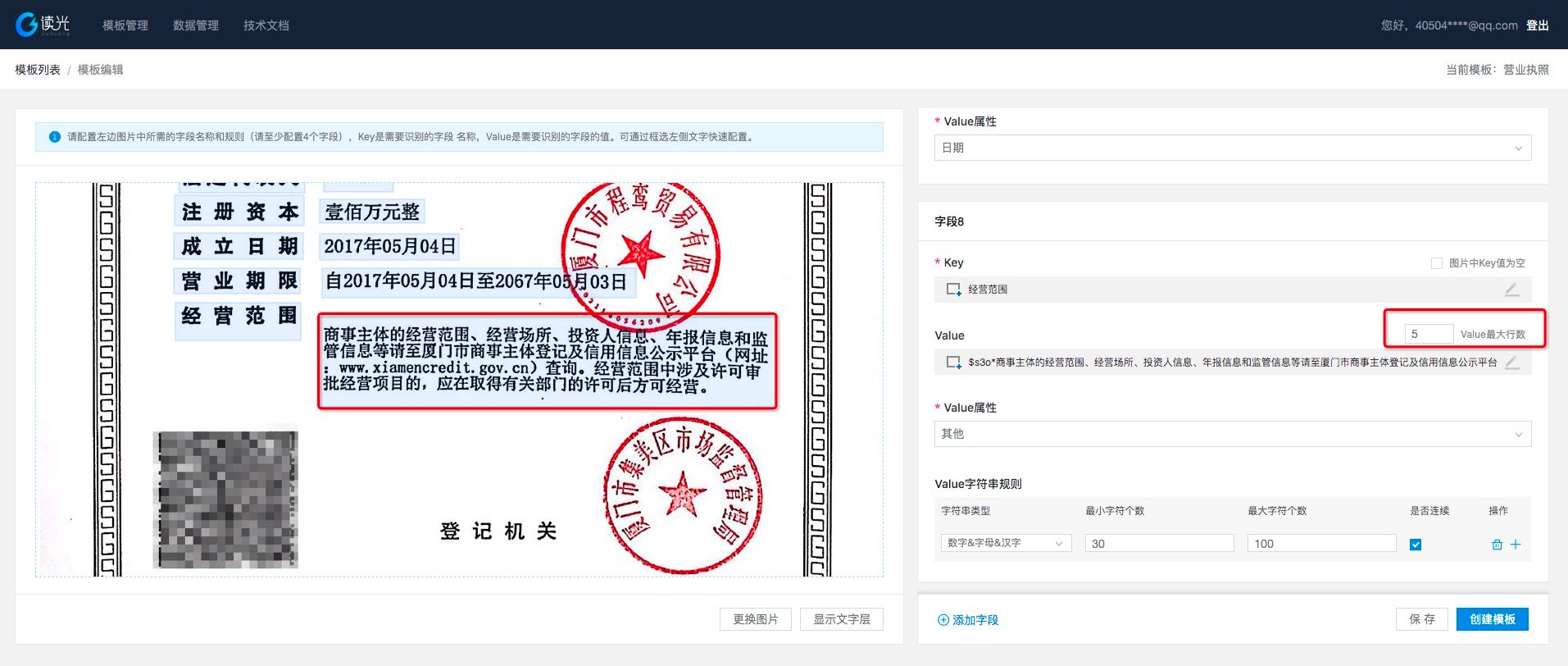
如图中经营范围显示4行,但根据经验可能最多有5行,因此右边配置上可能出现最多行数的可能。
- 需要声明的是:
- 使用KV结构模板至少需要标注4个有效字段
- 配置完后检查是否将所有字段已经配置到位
- 当所有步骤都完成后点击创建模板即可创建出一个初始模板啦~
2. 数据集与数据标注
数据集是为了进行模板的训练和评测使用。而有效的数据集需要对上传的图片进行一一标注,形成有效标准数据才能够投入训练使用。进入数据管理点击创建数据集,并选择相同类型的图片数据(建议至少30张图)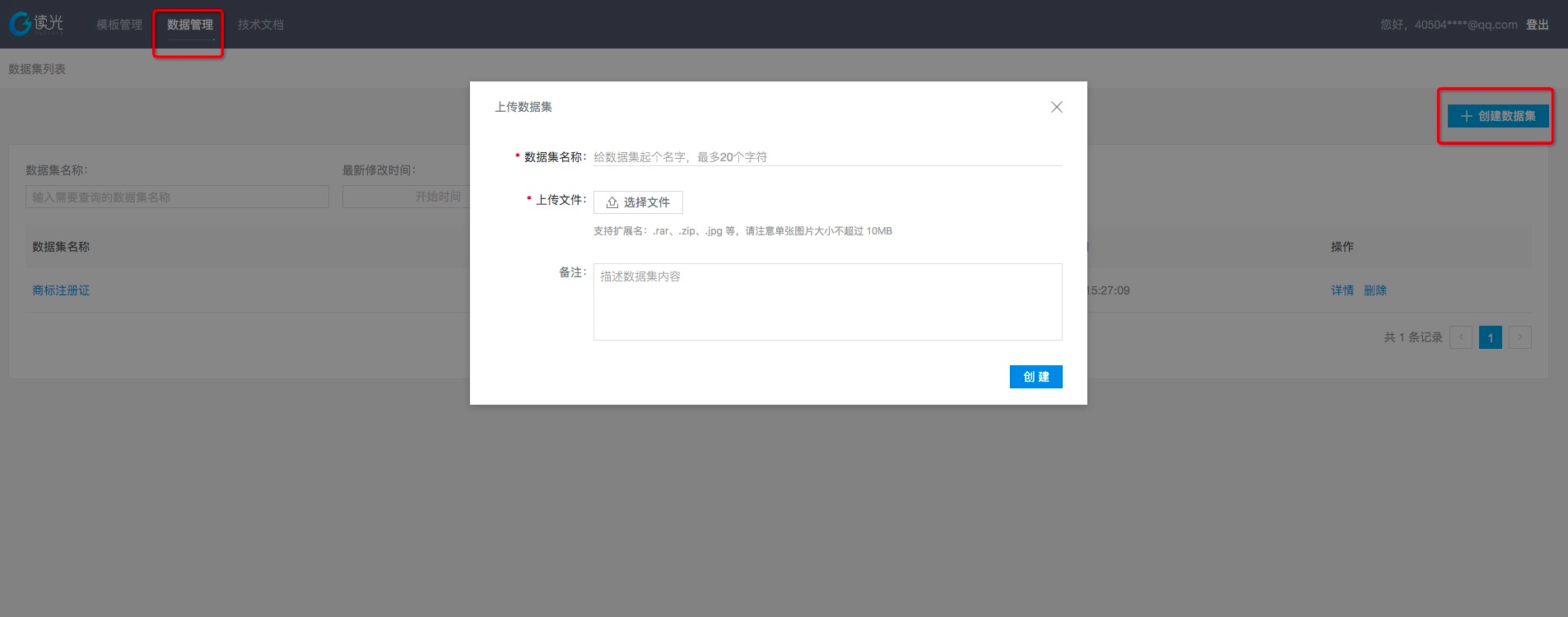
上传数据图片后,需要关联模板进行预识别。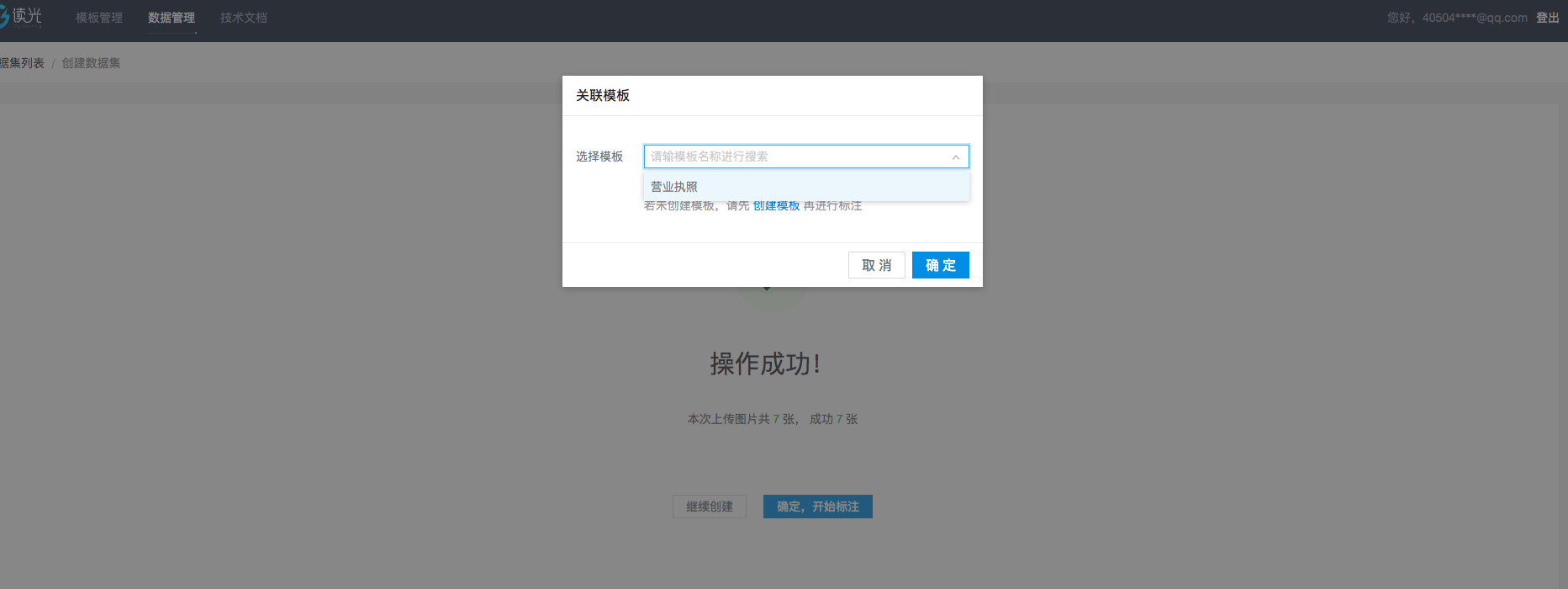
创建成功后,系统会将用户配置的模板进行预填入。用户需要仔细核对数据的准确性并进行修正。可通过框选的形式进行修正,若框选还不正确点击编辑按钮进行手动修正。 因为是标注数据,所以用户需要仔细核对标注的结果与图片文字一致,这一步将直接影响数据训练的准确度和统计的准确率。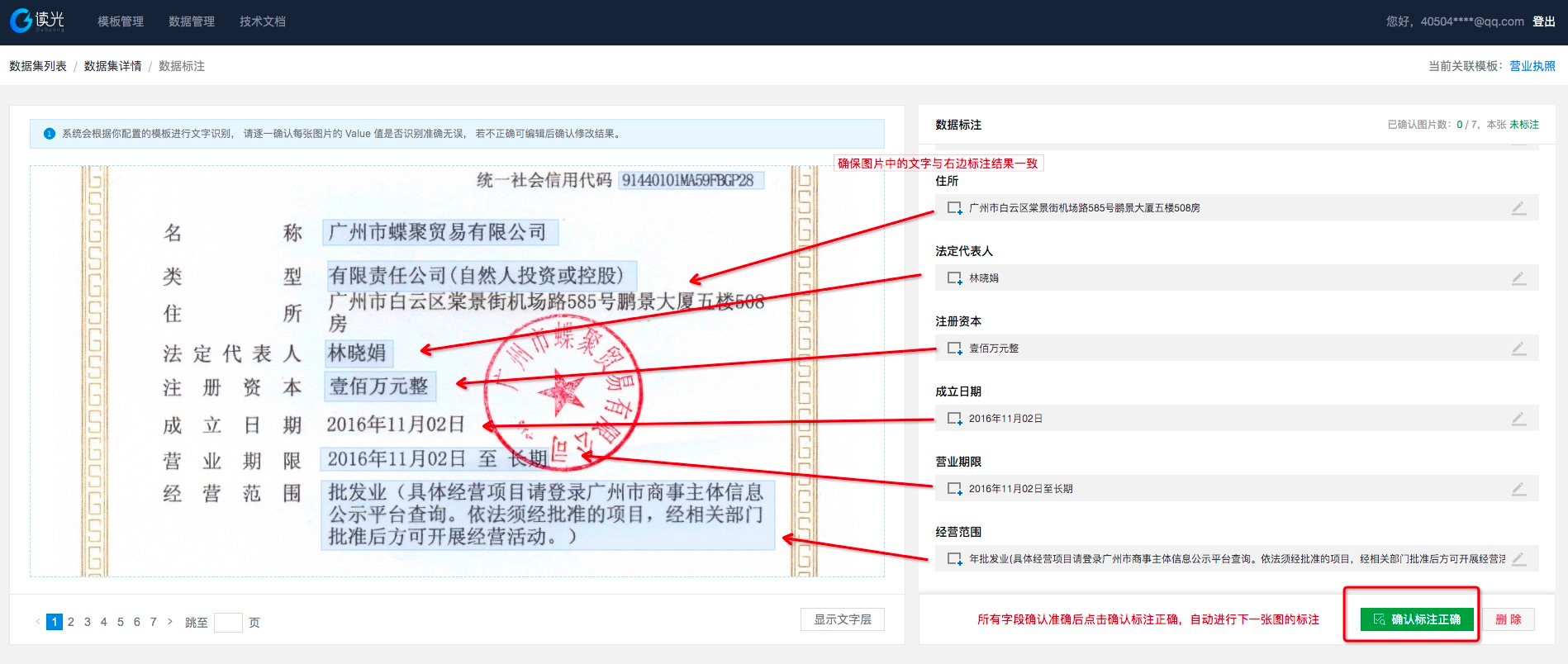 **
**
当标注一致后点击“确认标注正确”,自动进行下一张图的标注
若遇到图片质量特别模糊或者与该模板不一致的图片,建议直接删除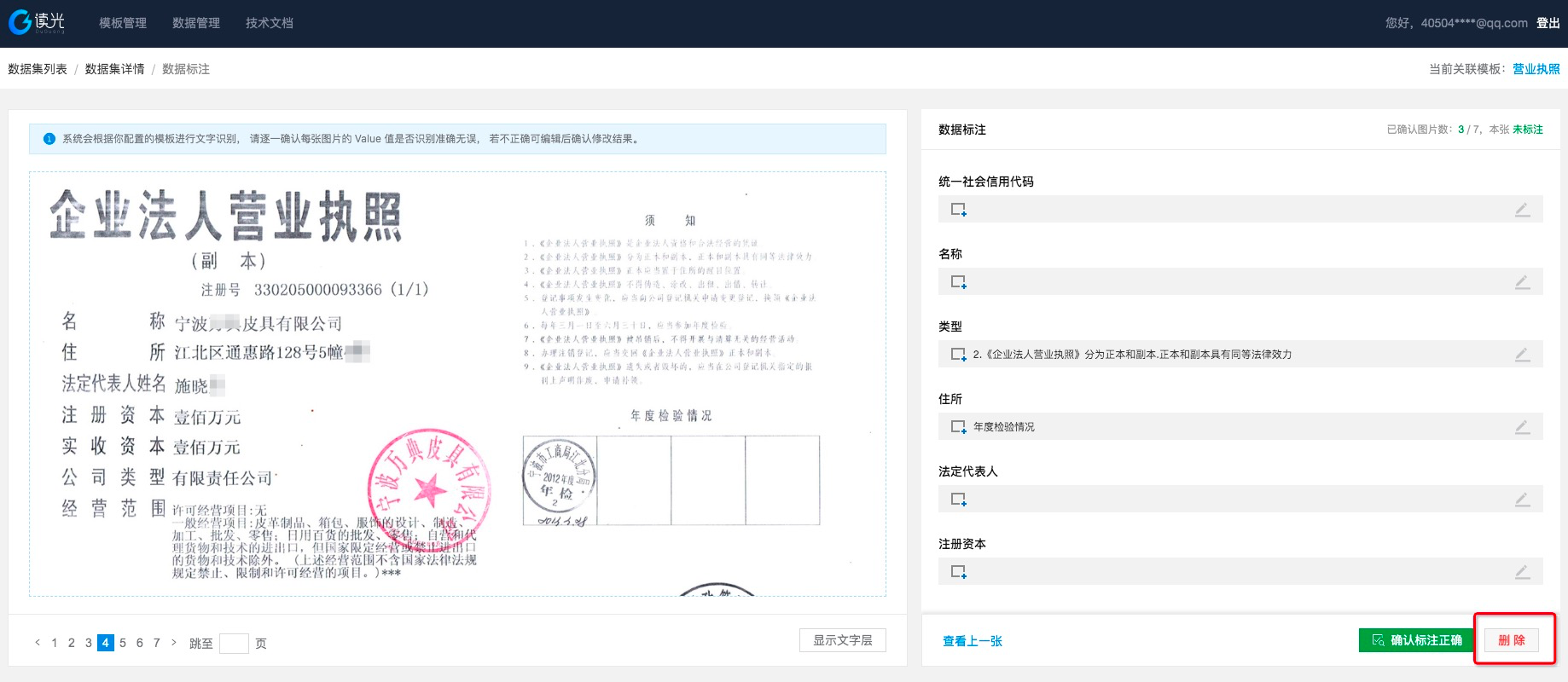
需要注意的是,有效的图片数必须大于30张才能进行模板的训练。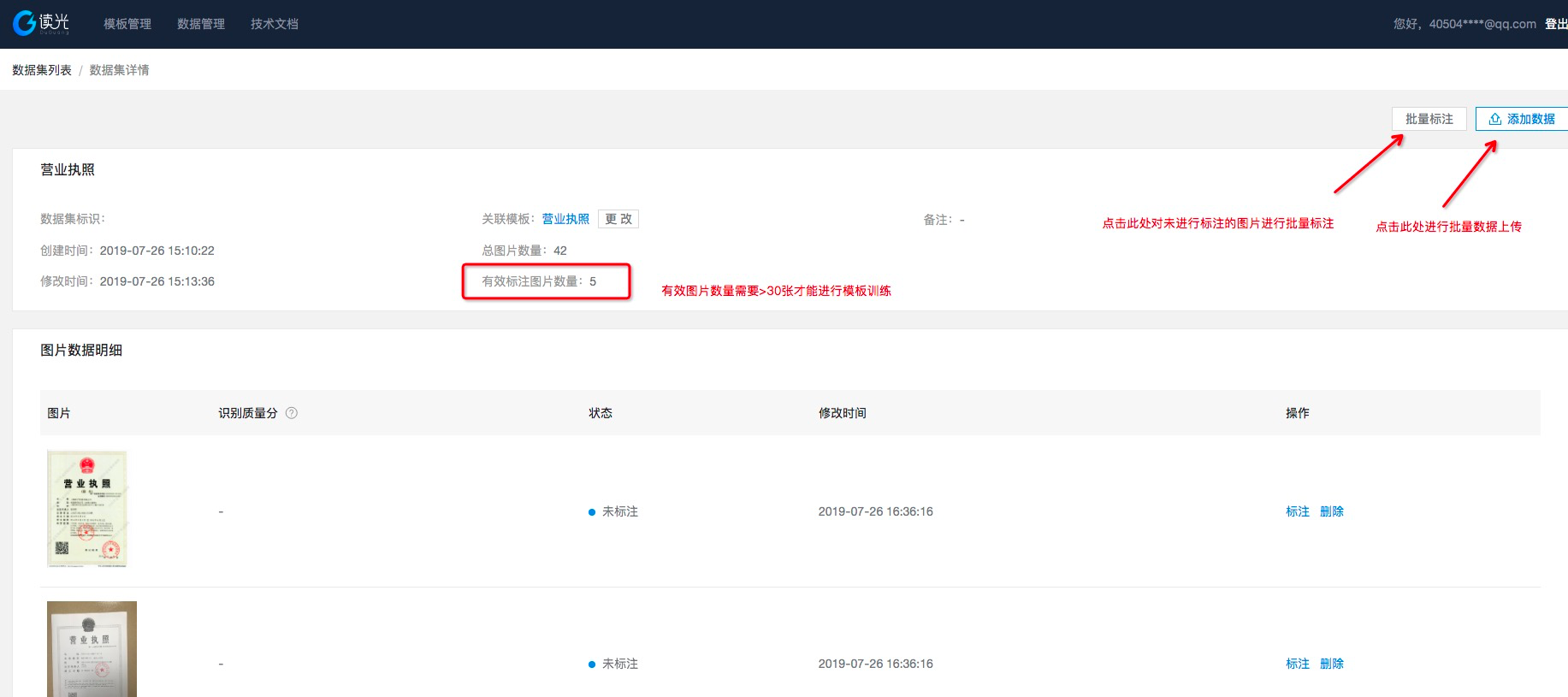
3. 模板训练
当可用的标注数据量达到一定值后,可回到模板管理页面进行模板的训练,点击训练按钮,并创建第一个训练批次。
系统默认会以8:2的训练测试比来进行数据的分配。训练开始后,等待几秒钟~几分钟可刷新一下页面,训练完后查看详情可看见本批次的评测统计结果。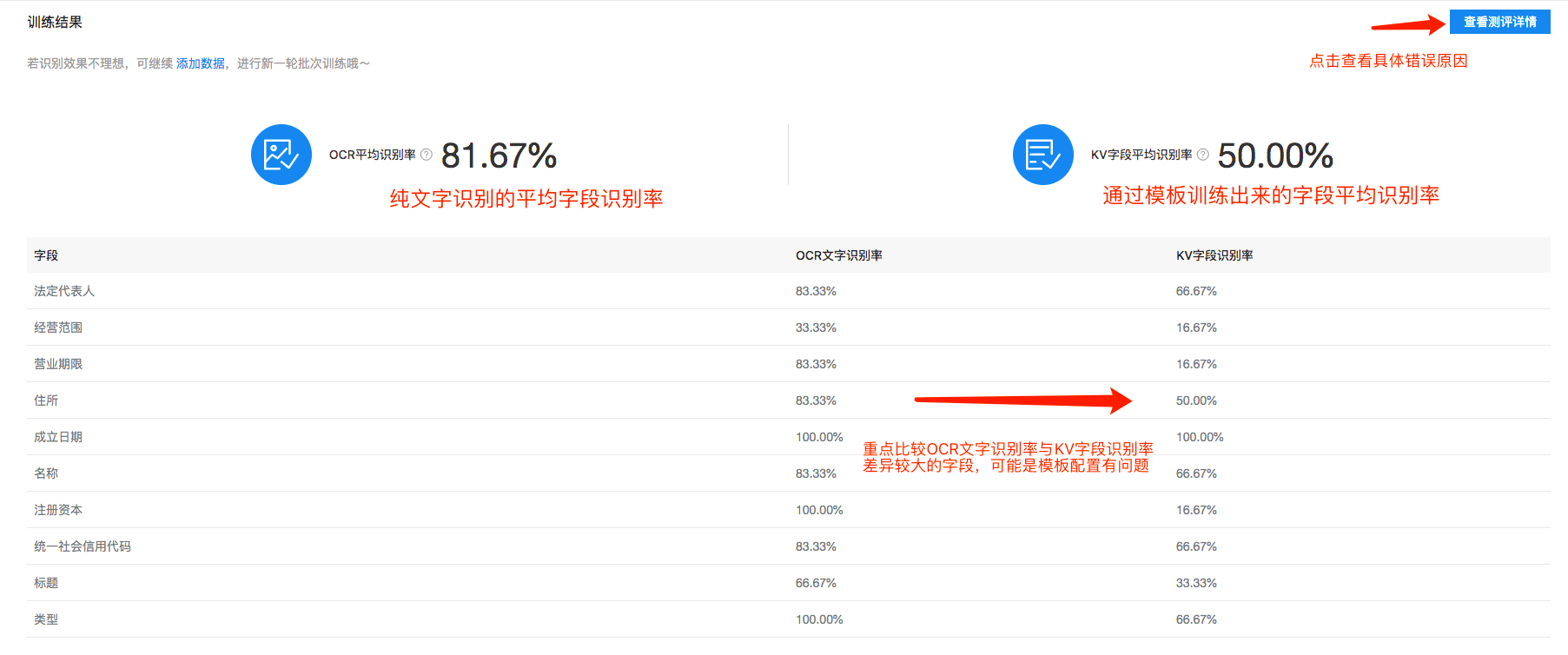
根据结果,可以看见个别字段的模板识别率较差,可以点击查看评测详情进行规律总结。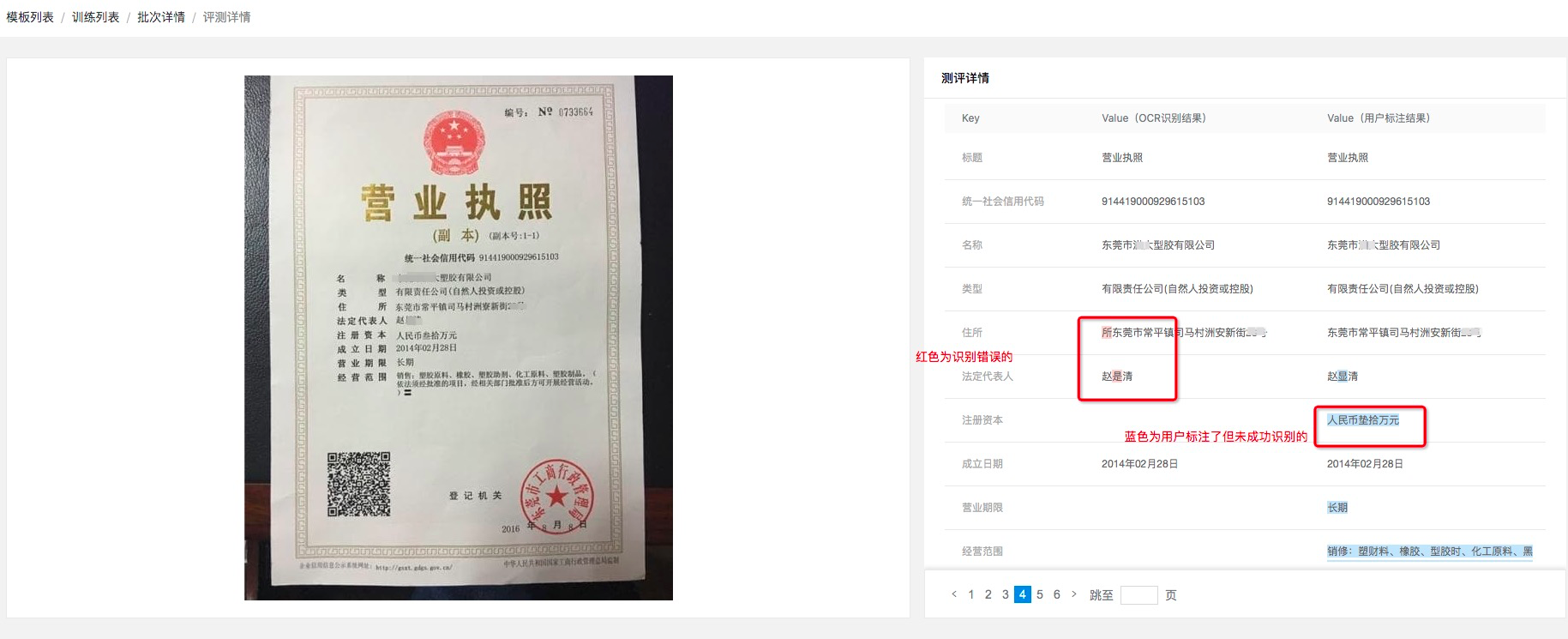
通常首次训练与用户配置的模板关系较大,如果发现模板配置有明显错误(如属性填写错误等)可重新编辑模板,并在数据集中上传图片后多训练几个批次,在这个过程中完成机器自学习的过程。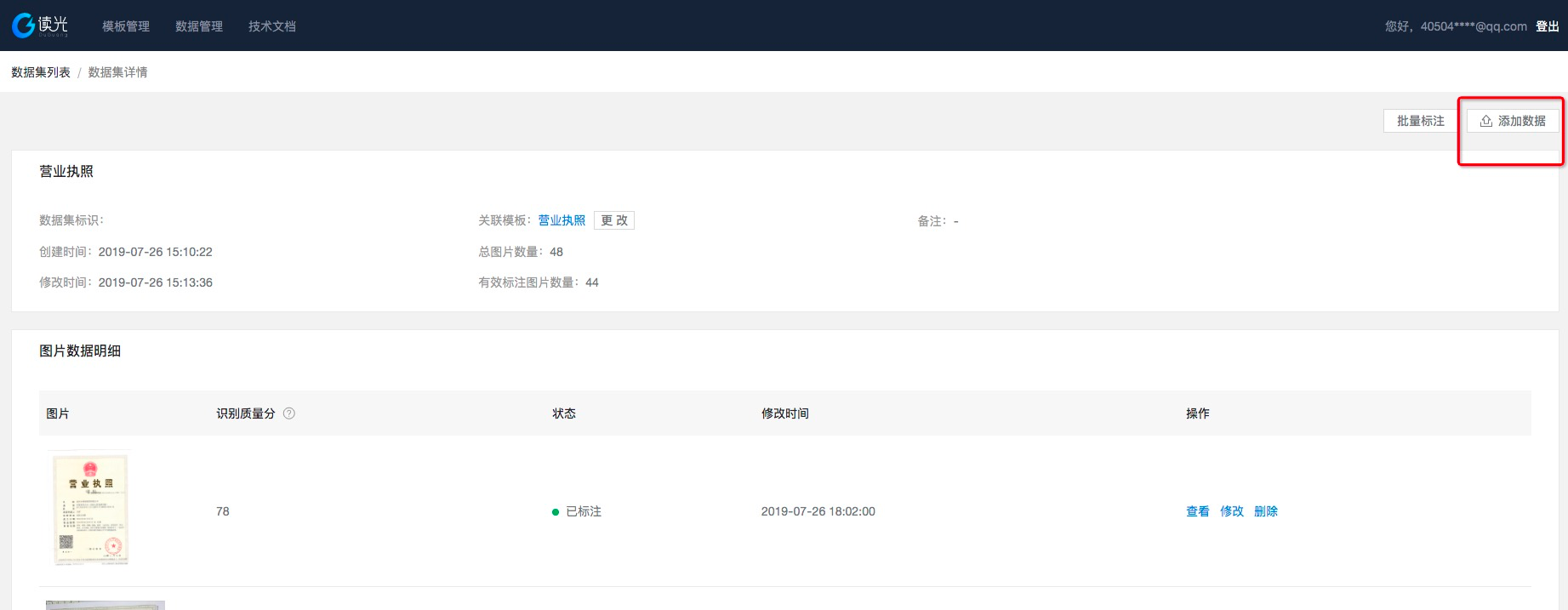
添加数据并进行标注后,新的训练批次会对所有的图片进行重新训练,是翻盖式训练。
返回模板列表,继续添加新的批次,新的训练结果跑出后即可进行版本之间的效果评测比对。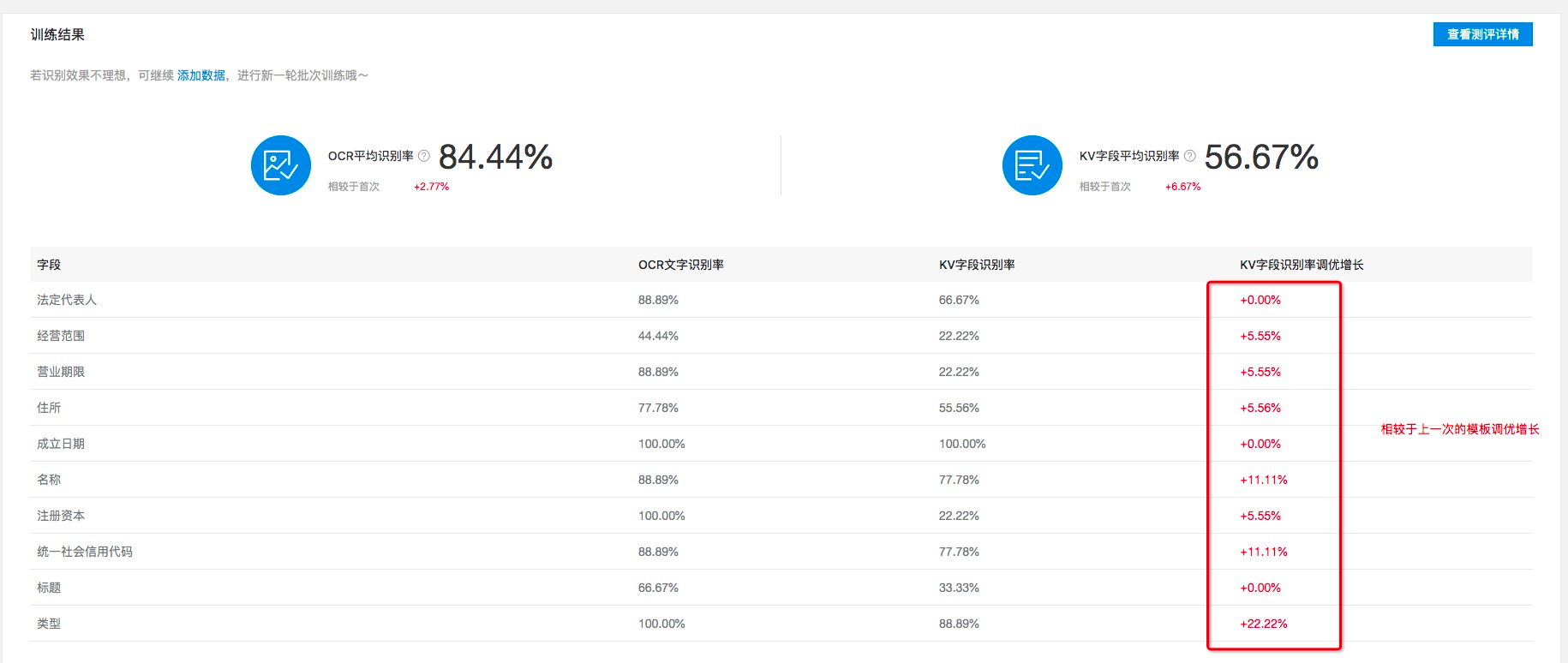
依次类推,直至训练到效果达到预期为止。
4. 模板评测与发布
通过训练的详情页可以看见每个批次的效果增长情况,用户可以选择效果满意的模板进行发布。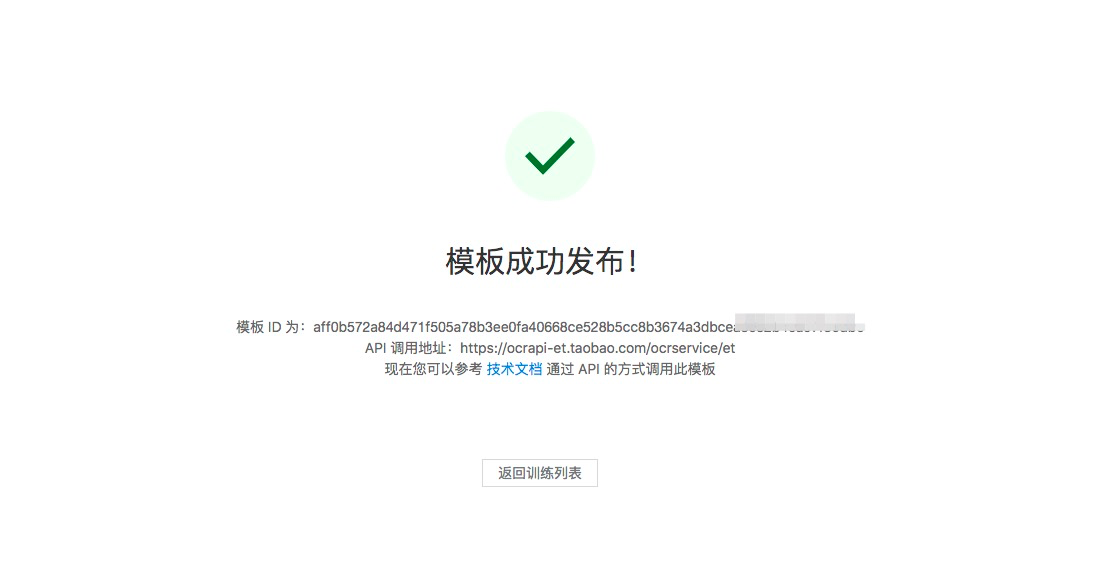
发布成功后,可通过公有云api进行500次免费调用。 若批量调用测试成功,可导出模板并联系读光团队进行线下模板API服务的提供。
公有云接口调用文档:
https://market.aliyun.com/products/57124001/cmapi032070.html?#sku=yuncode2607000001