1. 案例简介
本案例是在HaaS EDU K1上部署基于TFLite-Micro本地语音识别推理模型,主要有三个部分组成:
- 语音采集:接入模拟麦克风(Mic1输入);
- 语音识别:说出“打开”和“关闭”识别后,OLED将显示“Turn on...”和“Turn off”;
- 语音播报:执行指令的同时,播报本地TTS(mp3)。
2. 基础知识
2.1 基础目录结构
2.2 涉及知识点
* 唤醒词数据采集、模型训练、模型部署
- 设备端模拟MIC声音采样
- 设备端音频特征提取
- TFLite-Micro推理引擎应用
- 设备端命令识别、响应
- 设备端喇叭播放mp3文件
- 文件系统应用
- OLED显示字符
3. 方案介绍
3.1 硬件搭建
HaaS语音扩展板是专门为HaaS EDU K1教育神器打造的,无缝对接,即查即用,不过目前没有对外售卖,主要通过一些活动定向赠送。以下是使用HaaS语音扩展板的硬件图:

如果没有HaaS语音扩展板,同样可以购买麦克风和喇叭进行体验,请按照如下步骤接线:
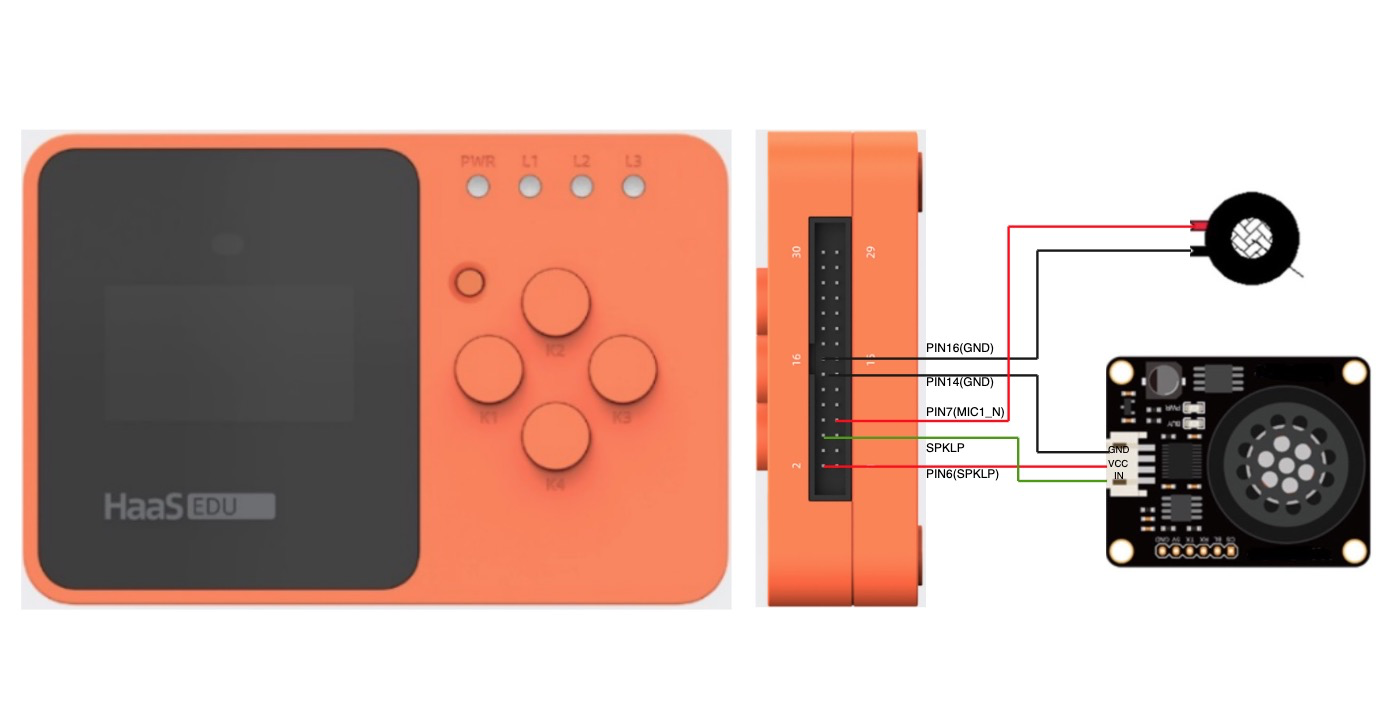
HaaS EDU K1硬件排线图请参考 https://help.aliyun.com/document_detail/205267.html
购买链接仅供参考!!我们不负责商家发货的品质保障等问题!!
| 名称 | 数量 | 参考链接 |
|---|---|---|
| HaaS EDU K1开发版 | 1 | HaaS EDU K1购买链接 |
| microUSB数据线 | 1 | 普通microusb线即可 |
| 模拟MIC | 1 | 模拟MIC参考链接 |
| 喇叭 | 1 | 喇叭参考链接 |
3.2 软件架构

* KWS Demo应用程序: 主要打通实现AI语音引擎的初始化,欢迎语播报。
- ai_agent组件:是AliOS Things上的AI引擎核心模块,后端接入不同的推理引擎,本案例中使用了TFLite-Micro推理引擎。
- uVoice组件:是AliOS Things上智能语音解决方案的核心组件,提供了本地音频,URL音频,TTS合成等基础功能,音频格式支持mp3, m4a, wav, opus等主流格式,本案例中使用它来进行本地mp3语料的响应播报。
- A2SA组件:是AliOS Things上音频服务框架,兼容ALSA应用接口访问,支持音频硬件驱动抽象,多音频驱动加载/卸载,VFS接口支持等功能。
## 3.3 设备端工作流程 在HaaS EDU K1上的整个工作流程如下图:

4. AliOS Things开发环境搭建
案例相关的代码下载、编译和固件烧录均依赖AliOS Things配套的开发工具 haas-studio ,所以首先需要参考《AliOS Things集成开发环境使用说明之搭建开发环境》,下载安装 haas-studio 。 待开发环境搭建完成后,可以按照以下步骤进行示例的测试。
4.1 案例代码下载
该案例相关的源代码下载可参考《AliOS Things集成开发环境使用说明之创建工程》。
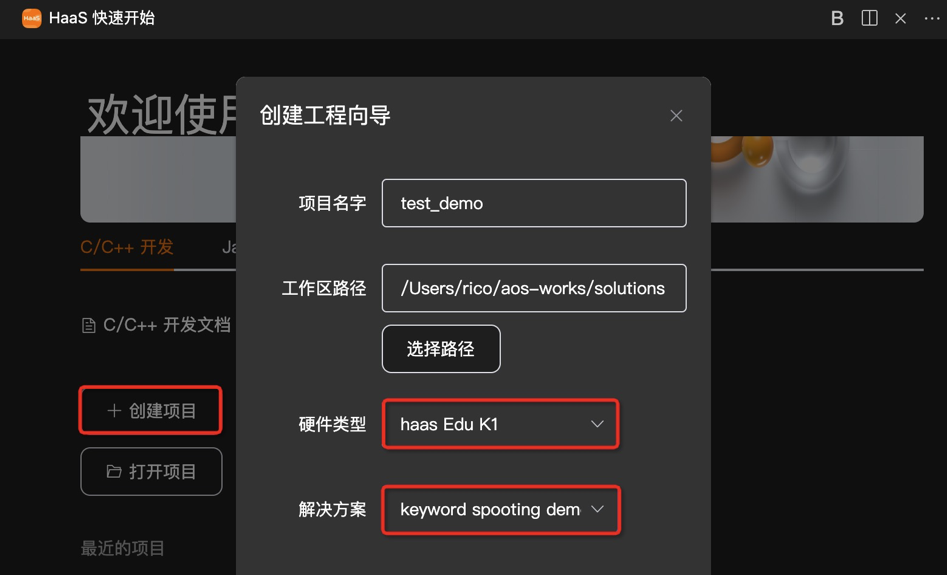
其中:
选择解决方案: “TFLite-Micro离线语音快捷词唤醒案例”或者“tflite_micro_speech_demo”
选择开发板: HaaS EDU K1
4.2 代码编译、烧录
– 固件编译方法可参考《AliOS Things集成开发环境使用说明之编译固件》。
4.2.1 文件件系统烧录
本组件例子中使用到到的本地语料存放在代码中hardware/chip/haas1000/prebuild/data/目录下mp3目录,除烧录tflite_micro_speech_demo image外,需烧录littlefs文件系统,请将hardware/chip/haas1000/package.yaml文件中以下代码段的注释打开:
– 固件烧录方法可参考《AliOS Things集成开发环境使用说明之烧录固件》。
4.3 打开串口
固件烧录完成后,可以通过串口查看示例的运行结果,打开串口的具体方法可参考《AliOS Things集成开发环境使用说明之查看日志》。
5. 案例体验
<video width="100%" style="max-width:800px" controls="controls" src="https://cloud.video.taobao.com/play/u/3903519387/p/1/e/6/t/1/324208098397.mp4"></video>
当程序烧录完成后,直接喊出“打开",“关闭”,就可以看到视频所示的效果。目前只支持近场唤醒,唤醒距离1米左右。如果听不到声音请逆时针选择喇叭蓝色旋钮调节音量至最大。
6. 自训练唤醒词
本案例是自训练了一个“打开”,“关闭”快捷唤醒词。本小节将带你训练一个新的快捷唤醒词。 从录音采集到部署到HaaS EDU K1的整个详细流程如下:

6.1 语料采集
语料采集是一个比较耗费人力的事情,通常商业化工程中语料收集有专人或专门的数据公司收集整理,这里提供了一个使用Python写一个录音工具,方便你快速录音。
>依赖项安装
>录音配置
- 语音文件长度一秒
- 单声道、16KHz、wav格式
- 快、中、慢三种不同速度进行录制
- 录制次数100次以上,次数越多效果越好
- 相对安静环境
6.1.1 唤醒词录制
录制时看到“开始录音,请说话......”即可立即说出唤醒词,比如“打开”、“关闭”。由于我们检测一秒的唤醒词,所以在注意要在一秒内说完整整个唤醒词,录制一次后会自动回放确认是否录制完整,如果录制完整,按回车键继续下一次录制,如果录制不完整或有其他杂音,按其他任意键删除刚才的录音再继续下一次录制。
>执行命令

毫无疑问,这个教学案例是教你如何录制一个人的声音,如果想要达到商业化的识别率,就至少需要500人以上的声音录制。如果仅仅录制你一个人的唤醒词,那么仅识别你的声音是可以的,但其他人在唤醒时的成功率就会低很多。这个案例重点是教你了解唤醒词训练部署的原理。
6.1.2 背景噪音录制
为了更好的识别,需要录制一些背景噪音,模型训练时会学习唤醒词和背景噪音的差别。背景噪音可以录制1~2分钟。模型训练时会自动从中随机选择片段作为背噪加入唤醒词中进行学习。
>执行命令
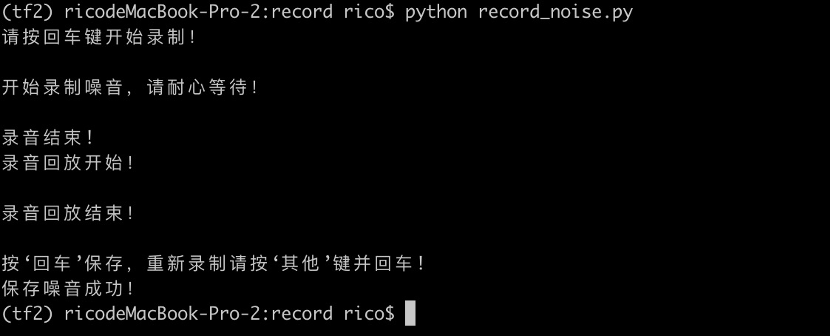
录制背景噪音,放到dataset/_background_noise_目录。
6.1.3 创建自己的数据集
训练脚本中默认采样的预训练数据集是Google发布的Speech Commands(语音命令)数据集,该数据集是英文数据集。这里我们以录制中文的“打开”,“关闭”为例,每个词录制100次。录制完成后分别命名为dakai和guanbi两个文件夹放入自定义的my_dataset目录,然后从Speech Commands中选择几个单词house、marvin、wow等唤醒词作为“未知”类别放入到my_only_dataset目录,它的作用是模型训练时能够从这些唤醒词中识别想要的dakai和guanbi命令,dakai和guanbi可以理解为正面示例,“未知”类别为反面示例。整个命令词个数尽量限制在十个以下,这样训练的时间不会过久。如果你有其他同样长度且与录音配置中格式一样的唤醒词,也可以加入进来。另外如果录制的是100次唤醒词,那么其他作为“未知”类别的唤醒词的录音示例个数也尽量在100左右。录制的背景噪音放入到_background_noise_目录,训练时脚本将自动从中随机选取一秒片段作为背景噪音加入到“无声”类别中。
6.2 模型训练
6.2.1 PC端训练
PC上在VSCode中使用jupyter notbook插件打开tflite_micro_speech_demo/micro_speech/train/train_micro_speech_model.ipynb进行其他唤醒词的训练。
前提:
参考《HaaS AI之VSCode中搭建Python虚拟环境》以及《在VSCode中搭建TensorFlow 2.0简单神经网络》搭建环境。
注意: 安装Tensorflow 1.x版本,非2.0版本。

6.2.2 阿里云PAI平台训练
如果PC性能有限,使用阿里云PAI平台进行训练也是一个不错的选择,PAI-DSW是一款云端机器学习开发IDE,为您提供交互式编程环境,适用于不同水平的开发者。你可以根据根据需要选择个人版、GPU特价版或探索者版(免费),相关使用手册DSW新手使用手册。 以使用DSW个人版为例:
- 登录PAI控制台。
- 在左侧导航栏,选择模型开发和训练 > 交互式建模(DSW)。
- 在页面左上方,选择目标地域。
- 在Notebook建模服务页面,单击创建实例。
- 在配置实例向导页面,配置参数,镜像选择tensorflow1.15-gpu-py36-cu101-ubuntu18.04版本。

6.2.3 模型配置
无论在什么平台上进行训练,脚本中需要对训练的参数进行一定的配置:
>唤醒词配置
WANTED_WORDS就是你训练的唤醒词。比如: WANTED_WORDS="yes, on",yes/on对应于数据集dataset目录的唤醒词语料文件夹。这里跟你你要训练的唤醒词修改。
>训练步数配置
如果你的唤醒词仅仅走数百条甚至数10条,那么训练的步数不用太久,修改: TRANINGS_STEPS="1200, 300" 如果你有上千条以上,训练的步数可以增加: TRANINGS_STEPS="15000, 3000" 为了防止训练欠拟合或者过拟合,训练的时间长短需要反复验证,找到最优的结果。
>数据集配置
如果使用自己的数据集,请修改: DATASET_DIR = './dataset/'
6.3 模型部署
模型部署在HaaS EDU K1上,主要有三个步骤:
- 模型替换:将模型文件model.cc替换micro_speech/micro_features/model.cc文件。
- 标签更新:在cc替换micro_speech/micro_features/micro_model_settings.cc中,将标签名更换为你训练的快捷词,比如“打开”、“关闭”。由于标签与模型的输出张量元素是按照顺序进行匹配的,因此,需要按照将标签提供给训练脚本的顺序列出这些标签。
- 业务逻辑更新:在micro_speech/command_responder.cc中根据标签更新相应的业务逻辑。目前在听到“打开”后,会打开HaaS EDU K1上R/G/B LED灯。你也可以修改逻辑比如通过WiFi打开远程的风扇或灯。这里可以充分发挥你的想象力打造一些比较有意思的场景应用。
7. 总结
本案例在HaaS EDU K1上基于TFLite-Micro推理引擎进行语音唤醒词的部署。也提供了从唤醒词采集到模型训练,模型部署的全链路开发流程,帮助您深入理解在低功耗MCU上如何进行离线语音识别的开发部署,期待您打造更多属于你的唤醒词应用。