定时任务介绍
定时任务开发指南
tae目前提供三种形式的任务框架:简单的Task开发以及预取数据的Task开发,以及分片执行的Task开发
依赖
|
<dependency> <groupId>com.alibaba.appengine</groupId> <artifactId>services-jae-api</artifactId> <version>1.0.1-SNAPSHOT</version> </dependency> <dependency> <groupId>com.alibaba.appengine</groupId> <artifactId>services-lib-api</artifactId> <version>1.0.1-SNAPSHOT</version> </dependency> |
简单的定时任务
|
import com.alibaba.appengine.api.task.SimpleTask;
public class MyTask implements SimpleTask {
public String run(String[] args) throws Exception { ... } } |
|
com.xxx.yyy.MySimpleTask |
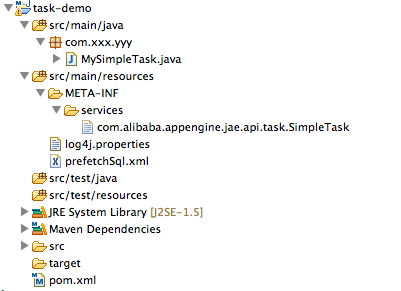
提示:zip包中的全部.jar都会被task容器所加载,是否放在文件夹中对加载没有影响。 zip的示例结构如下
预取数据的定时任务
原理
- 使用“预取数据的Task开发”常见的场景为数据的ETL任务,如数据从RDS推送表同步至用户自己的业务表,从TOP接口拉取数据等。此时Task容器需要用户实现两阶段的逻辑:
- 数据提取的逻辑prefetchSql.xml 用户通过编写数据预取xml,描述如何从数据源中提取数据。数据提取源包括RDS表,御膳房的数据拉取接口,TOP接口,消息队列等。目前仅支持RDS表的数据源。而且暂不提供分页 or 分片处理的语义(用于处理数据量大的场景)。
- 数据处理的逻辑AbstractPrefetchTask 用户把提取的原始数据在AbstractPrefetchTask的指定方法中进行处理,并允许加载至RDS数据库、cache、OSS、REST接口。
开发步骤
第一步:通过配置SQL完成数据集的预取 默认的描述文件路径:classpath:prefetchSql.xml,也可以通过Override AbstractPrefetchTask的getPrefetchSqlPath方法自定义该配置文件的路径。 用户可以完整利用ibatis风格的dynamic statement写出复杂逻辑的SQL以满足复杂需求。Jae任务容器的预取描述只是参考ibatis风格,不需要用户因此引入任何ibatis的依赖。 用户在编写在SQL文件的过程中,可以引用任务框架提供的内建变量(使用##或者$$进行引用)。目前提供三个内建变量
- order 多实例并发执行一个任务时,本实例的编号,单实例场景下无意义,int类型
- total 多实例并发执行一个任务时,总实例数目,单实例场景下无意义,int类型
- fireTime 任务的预计开始时间,注意:非实际执行时间,而是定时表达式计算得出的预计时间,java.util.Date类型。 示例的prefetchSql.xml文件如下(引用了内置变量fireTime):
|
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE prefetch SYSTEM "http://jae.alibaba.com/dtd/prefetch-sql-map.dtd"> <prefetch> select from sys_info.xxx where <![CDATA[modified <= DATE_SUB(#fireTime#,INTERVAL 1 MINUTE) ]]> and <![CDATA[modified > #fireTime# ]]> </prefetch> |
第二步:任务需要扩展实现AbstractPrefetchTask
String[]参数args:第一个元素是预留参数,第二个是sharding相关的总实例数total,第三个是sharding相关的实例编号order,第四个是预计开始时间。
假设用户通过预取阶段从数据库捞出500条记录,则PrefetchSet对象代表了500条记录的全集,Row对象代表了其中的一条记录。AbstractPrefetchTask的中各方法的被task容器调用的次序如下(实例伪代码):
|
args=task容器上下文中获取的数据 PrefetchSet ps=数据提取源中获取的数据; beforeRun(args,ps); for(Row r:ps){ run(args,r); } String ret=afterRun(args,ps); |
在beforeRun和afterRun方法中,用户可以对数据全集进行操作,但是无法调用任何外部服务(数据库、缓存、TOP等);在run方法中,用户只可以对单挑数据进行操作,可以调用容器提供的外部服务。这主要是处于数据安全的考虑。因此ETL任务中L(数据加载)阶段,只能在run方法中实现。整个任务结束任务容器会保存一些描述性的信息以供查阅,即afterRun方法的返回值。
AbstractPrefetchTask的方法签名如下:
|
/** 数据源名称,若没有Override,取缺省数据源
@return / public String getDataSourceName() { return null; }
/** 获取预取Sql配置路径 / public String getPrefetchSqlPath() { return "prefetchSql.xml"; }
/** 对预取的数据集可以做预处理,缺省可以什么都不做
@param ps 预取的数据集 / public PrefetchSet beforeRun(String[] args, PrefetchSet ps) { // by default, do nothing return ps; }
/** 遍历预取的数据集,以单行数据交由该方法做处理
@param args @param row 单行预取的数据 @return / public abstract void run(String[] args, Row row);
/** 在全部预取的数据集都处理完毕之后执行,缺省可以什么都不做 */ public String afterRun(String[] args, PrefetchSet ps) { // by default, do nothing return null; } |
第三步:向容器暴露服务
使用java原生的spi机制向JAE任务容器暴露AbstractPrefetchTask的实现类,因此需要添加如下文件: META-INF/services/com.alibaba.appengine.jae.api.task.AbstractPrefetchTask
|
com.xxx.yyy.MyPrefetchTask |
(注意:文件内容就是用户实现类的完整类名,这里以demo中的com.xxx.yyy.MyPrefetchTask示例。具体原理请自行google “java spi”)
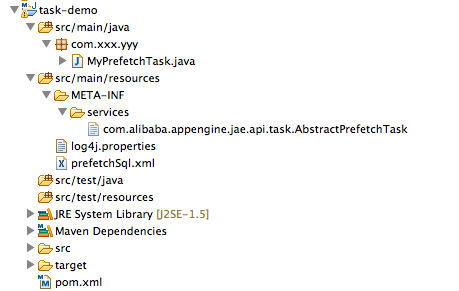
第四步:示例的项目结构如下:
第五步:用户的工程编译的jar,同时相关的依赖jar一起打包为zip,通过JAE后台上传。
提示:zip包中的全部.jar都会被task容器所加载,是否放在文件夹中对加载没有影响。 zip的示例结构如下:
分片式定时任务
分片定时任务可以把数据的收集和数据的处理分成两个阶段来处理,第一阶段为要处理的数据收集的阶段,每批收集不超过2000条数据,这个数据string的形式表示,返回后我们负责保存到数据库中,一直调用收集方法(take),直到收集方法的中的结束标识设置为true。收集阶段结束后进入数据处理阶段,每次以出2000条给任务的处理方法(run)来处理这些数据,直到所有数据处理处理完成,任务结束。
第一步,自己写的任务处理类extends AbstractShardingTask进行开发自己的任务:
其中args[] = {“参数”, null, null, FireTime}, 由于之前args[1]和args[2]是提供给其它任务类型使用的,对于分片任务是null,args[0]对于take方法是告诉用户收集到第几批了从0开始,args[0]对于run方法是本批需要处理的数据的json格式。
例如:
public class MyShardingTask extends AbstractShardingTask {
@Override
public ShardingSet take(String[] args) {
。。。。。。
ShardingSet set = new ShardingSet(finished);//这个finished表示这一批数据收集完后是否就结束了,如果没有没结束还需要收集下一批数据就设置成false,如果这已经是最后一批则True
set.add("a”);//这里面每次放进去的数据不能超过2000个,超过2000个就直接抛异常了
set.add("b");
set.add("c”);
set.
return set;
}
@Override
public String run(String[] args) {
。。。。。。
return "OK";
}
}
第二步,配置该类到项目中的改文件 main/resources/META-INF/services/com.alibaba.appengine.jae.api.task.AbstractShardingTask
文件内容就写你那个类的全路径,例如:
com.xxx.yyy.MyShardingTask
第三步,打包
打包的时候要把自己类和依赖的jar全部打出来,把所有这些jar打成一个zip
例如maven的这个插件可以把所有依赖的jar也打出来
<build>
用这个插件打完包后,target目录下面就有你自己的jar和你依赖的那些jar了,把这些jar全部打到一个zip文件中就可以上传了。
日志
Jae支持基于单次任务执行的日志查询。log4j配置文件中请使用Jae指定的任务appender,如下: 注意,直接拷贝可能会拷到pdf中的不可见字符,请小心。
|
log4j.rootLogger = INFO,logAppender |
本地开发环境
下载后修改service-conf/service-config.properties文件,服务配置格式和web应用的ace4j-private.properties格式一样
执行run.bat(linux下面是执行run.sh),可以启动一次任务执行,会提示你让你输入任务所在的目录。
如果定时任务的代码所在目录是不变,不想每次输入可以修改run.bat,把你的定时任务所在的位置写在这里这个双引号中:set WORKER_BASE=""
DEMO下载